 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoarse-to-Fine Recursive Speech Separation for Unknown Number of Speakers
Paper and Code
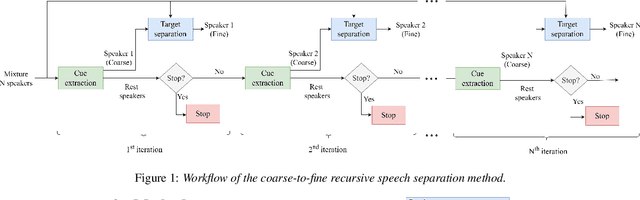
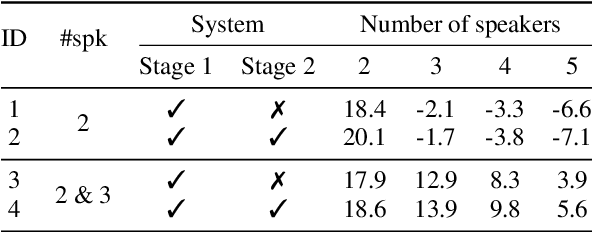
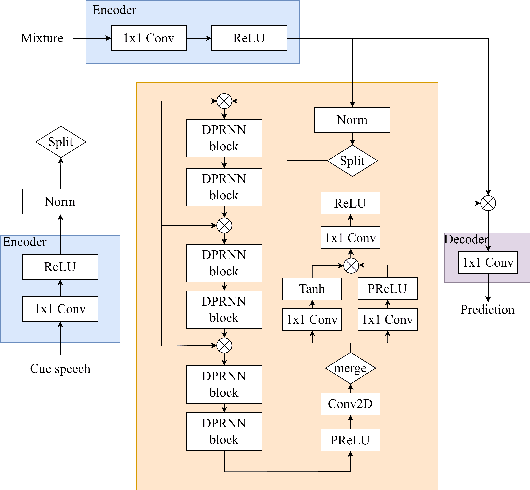
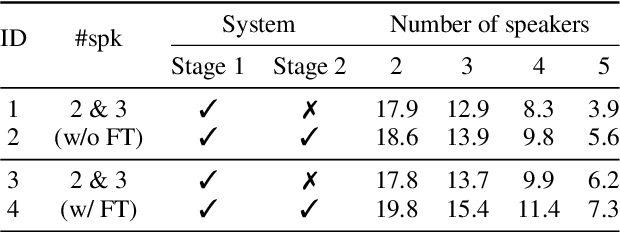
The vast majority of speech separation methods assume that the number of speakers is known in advance, hence they are specific to the number of speakers. By contrast, a more realistic and challenging task is to separate a mixture in which the number of speakers is unknown. This paper formulates the speech separation with the unknown number of speakers as a multi-pass source extraction problem and proposes a coarse-to-fine recursive speech separation method. This method comprises two stages, namely, recursive cue extraction and target speaker extraction. The recursive cue extraction stage determines how many computational iterations need to be performed and outputs a coarse cue speech by monitoring statistics in the mixture. As the number of recursive iterations increases, the accumulation of distortion eventually comes into the extracted speech and reminder. Therefore, in the second stage, we use a target speaker extraction network to extract a fine speech based on the coarse target cue and the original distortionless mixture. Experiments show that the proposed method archived state-of-the-art performance on the WSJ0 dataset with a different number of speakers. Furthermore, it generalizes well to an unseen large number of speakers.