 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoalesced Multi-Output Tsetlin Machines with Clause Sharing
Paper and Code
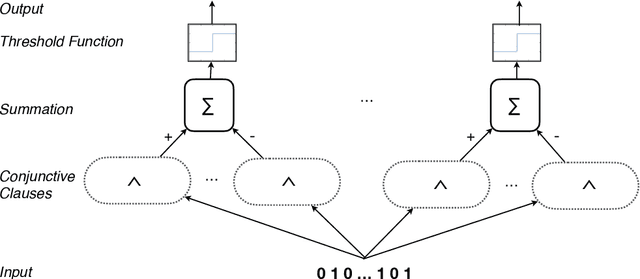


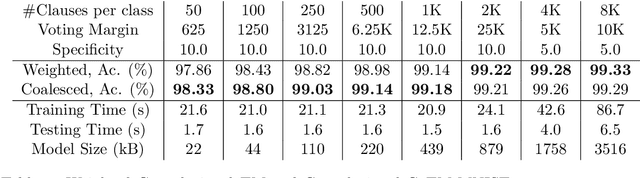
Using finite-state machines to learn patterns, Tsetlin machines (TMs) have obtained competitive accuracy and learning speed across several benchmarks, with frugal memory- and energy footprint. A TM represents patterns as conjunctive clauses in propositional logic (AND-rules), each clause voting for or against a particular output. While efficient for single-output problems, one needs a separate TM per output for multi-output problems. Employing multiple TMs hinders pattern reuse because each TM then operates in a silo. In this paper, we introduce clause sharing, merging multiple TMs into a single one. Each clause is related to each output by using a weight. A positive weight makes the clause vote for output $1$, while a negative weight makes the clause vote for output $0$. The clauses thus coalesce to produce multiple outputs. The resulting coalesced Tsetlin Machine (CoTM) simultaneously learns both the weights and the composition of each clause by employing interacting Stochastic Searching on the Line (SSL) and Tsetlin Automata (TA) teams. Our empirical results on MNIST, Fashion-MNIST, and Kuzushiji-MNIST show that CoTM obtains significantly higher accuracy than TM on $50$- to $1$K-clause configurations, indicating an ability to repurpose clauses. E.g., accuracy goes from $71.99$% to $89.66$% on Fashion-MNIST when employing $50$ clauses per class (22 Kb memory). While TM and CoTM accuracy is similar when using more than $1$K clauses per class, CoTM reaches peak accuracy $3\times$ faster on MNIST with $8$K clauses. We further investigate robustness towards imbalanced training data. Our evaluations on imbalanced versions of IMDb- and CIFAR10 data show that CoTM is robust towards high degrees of class imbalance. Being able to share clauses, we believe CoTM will enable new TM application domains that involve multiple outputs, such as learning language models and auto-encoding.