 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCo-Training for Unsupervised Domain Adaptation of Semantic Segmentation Models
Paper and Code
May 31, 2022

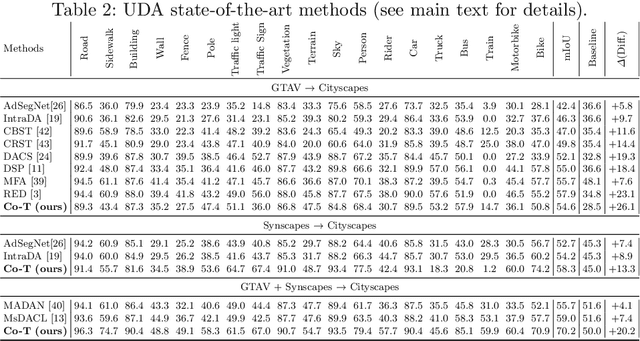
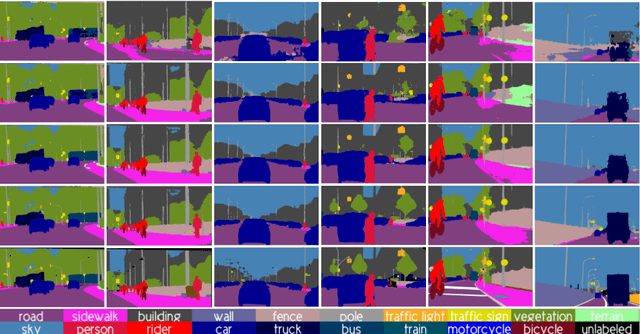
Semantic image segmentation is addressed by training deep models. Since supervised training draws to a curse of human-based image labeling, using synthetic images with automatically generated ground truth together with unlabeled real-world images is a promising alternative. This implies to address an unsupervised domain adaptation (UDA) problem. In this paper, we proposed a new co-training process for synth-to-real UDA of semantic segmentation models. First, we design a self-training procedure which provides two initial models. Then, we keep training these models in a collaborative manner for obtaining the final model. The overall process treats the deep models as black boxes and drives their collaboration at the level of pseudo-labeled target images, {\ie}, neither modifying loss functions is required, nor explicit feature alignment. We test our proposal on standard synthetic and real-world datasets. Our co-training shows improvements of 15-20 percentage points of mIoU over baselines, so establishing new state-of-the-art results.