 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCo-Teaching for Unsupervised Domain Adaptation and Expansion
Paper and Code

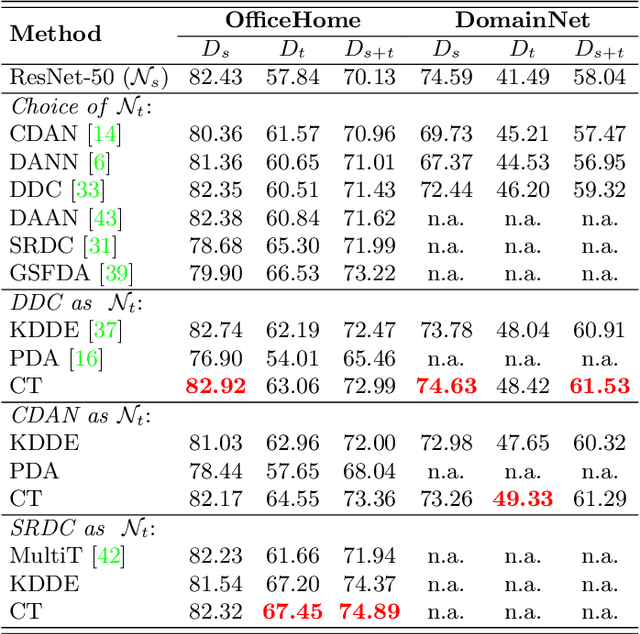
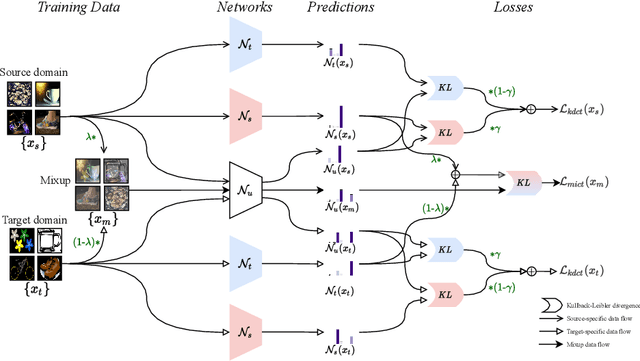
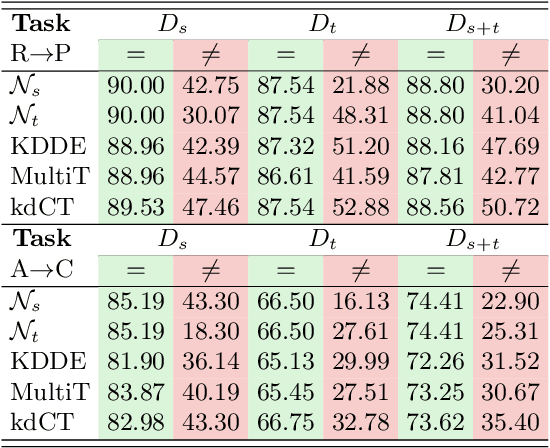
Unsupervised Domain Adaptation (UDA) is known to trade a model's performance on a source domain for improving its performance on a target domain. To resolve the issue, Unsupervised Domain Expansion (UDE) has been proposed recently to adapt the model for the target domain as UDA does, and in the meantime maintain its performance on the source domain. For both UDA and UDE, a model tailored to a given domain, let it be the source or the target domain, is assumed to well handle samples from the given domain. We question the assumption by reporting the existence of cross-domain visual ambiguity: Due to the lack of a crystally clear boundary between the two domains, samples from one domain can be visually close to the other domain. We exploit this finding and accordingly propose in this paper Co-Teaching (CT) that consists of knowledge distillation based CT (kdCT) and mixup based CT (miCT). Specifically, kdCT transfers knowledge from a leader-teacher network and an assistant-teacher network to a student network, so the cross-domain visual ambiguity will be better handled by the student. Meanwhile, miCT further enhances the generalization ability of the student. Comprehensive experiments on two image-classification benchmarks and two driving-scene-segmentation benchmarks justify the viability of the proposed method.