 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCMSAOne@Dravidian-CodeMix-FIRE2020: A Meta Embedding and Transformer model for Code-Mixed Sentiment Analysis on Social Media Text
Paper and Code
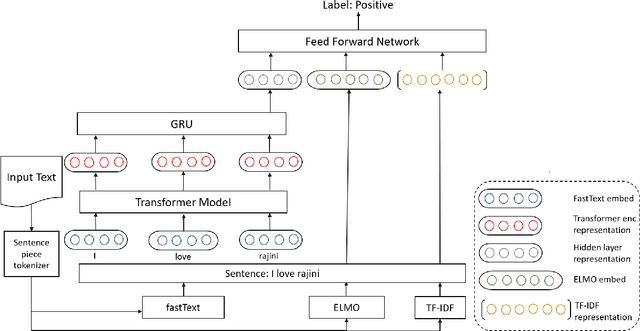


Code-mixing(CM) is a frequently observed phenomenon that uses multiple languages in an utterance or sentence. CM is mostly practiced on various social media platforms and in informal conversations. Sentiment analysis (SA) is a fundamental step in NLP and is well studied in the monolingual text. Code-mixing adds a challenge to sentiment analysis due to its non-standard representations. This paper proposes a meta embedding with a transformer method for sentiment analysis on the Dravidian code-mixed dataset. In our method, we used meta embeddings to capture rich text representations. We used the proposed method for the Task: "Sentiment Analysis for Dravidian Languages in Code-Mixed Text", and it achieved an F1 score of $0.58$ and $0.66$ for the given Dravidian code mixed data sets. The code is provided in the Github https://github.com/suman101112/fire-2020-Dravidian-CodeMix.