Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCMNEROne at SemEval-2022 Task 11: Code-Mixed Named Entity Recognition by leveraging multilingual data
Paper and Code
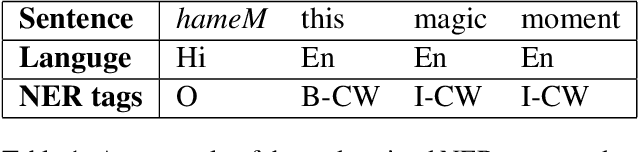
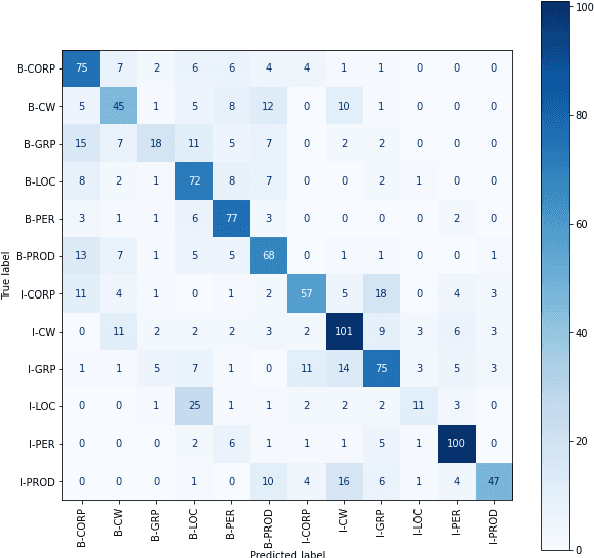
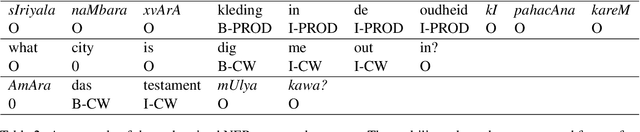
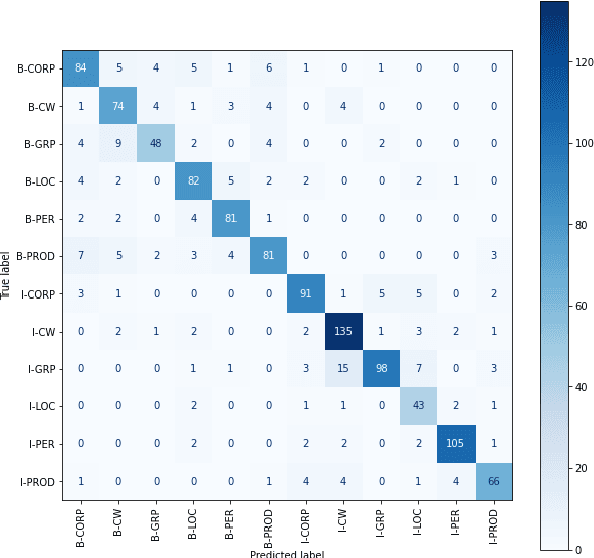
Identifying named entities is, in general, a practical and challenging task in the field of Natural Language Processing. Named Entity Recognition on the code-mixed text is further challenging due to the linguistic complexity resulting from the nature of the mixing. This paper addresses the submission of team CMNEROne to the SEMEVAL 2022 shared task 11 MultiCoNER. The Code-mixed NER task aimed to identify named entities on the code-mixed dataset. Our work consists of Named Entity Recognition (NER) on the code-mixed dataset by leveraging the multilingual data. We achieved a weighted average F1 score of 0.7044, i.e., 6% greater than the baseline.
* SemEval 2022 Task 11: MultiCoNER Multilingual Complex Named Entity
Recognition, NAACL, 2022
View paper on