Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClusterTabNet: Supervised clustering method for table detection and table structure recognition
Paper and Code
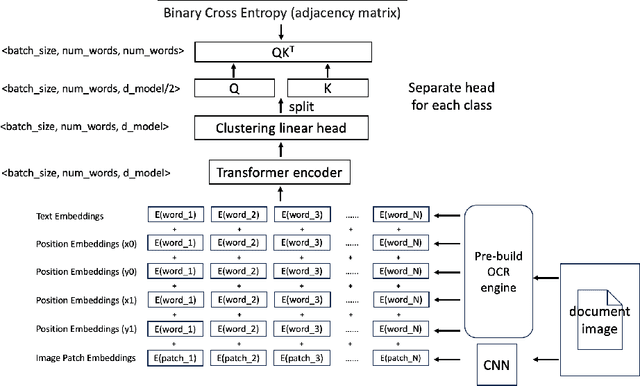
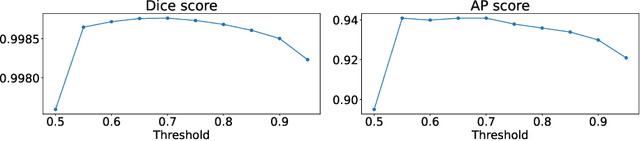
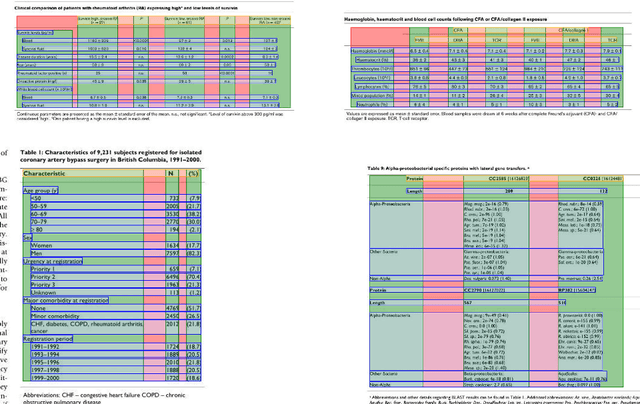

We present a novel deep-learning-based method to cluster words in documents which we apply to detect and recognize tables given the OCR output. We interpret table structure bottom-up as a graph of relations between pairs of words (belonging to the same row, column, header, as well as to the same table) and use a transformer encoder model to predict its adjacency matrix. We demonstrate the performance of our method on the PubTables-1M dataset as well as PubTabNet and FinTabNet datasets. Compared to the current state-of-the-art detection methods such as DETR and Faster R-CNN, our method achieves similar or better accuracy, while requiring a significantly smaller model.
* 15 pages, 4 figures, submitted. The code will be released at
https://github.com/SAP-samples
View paper on