 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCluster-based Mention Typing for Named Entity Disambiguation
Paper and Code
Sep 23, 2021

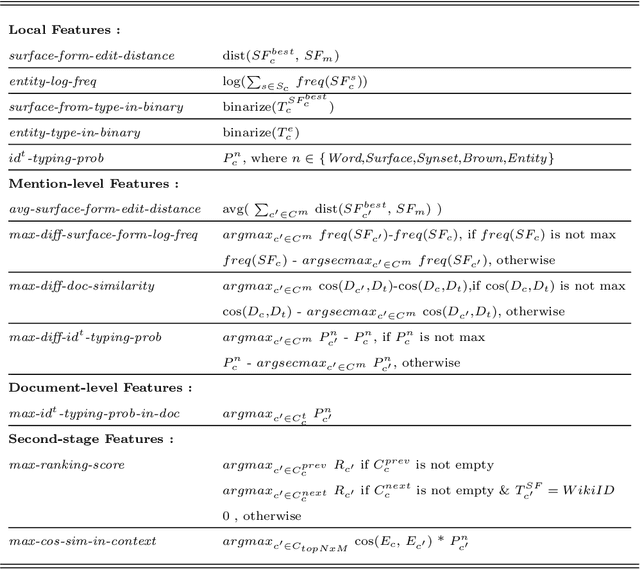
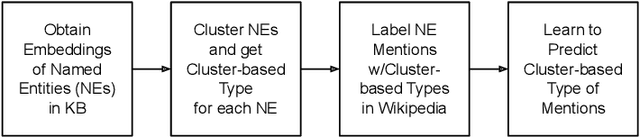
An entity mention in text such as "Washington" may correspond to many different named entities such as the city "Washington D.C." or the newspaper "Washington Post." The goal of named entity disambiguation is to identify the mentioned named entity correctly among all possible candidates. If the type (e.g. location or person) of a mentioned entity can be correctly predicted from the context, it may increase the chance of selecting the right candidate by assigning low probability to the unlikely ones. This paper proposes cluster-based mention typing for named entity disambiguation. The aim of mention typing is to predict the type of a given mention based on its context. Generally, manually curated type taxonomies such as Wikipedia categories are used. We introduce cluster-based mention typing, where named entities are clustered based on their contextual similarities and the cluster ids are assigned as types. The hyperlinked mentions and their context in Wikipedia are used in order to obtain these cluster-based types. Then, mention typing models are trained on these mentions, which have been labeled with their cluster-based types through distant supervision. At the named entity disambiguation phase, first the cluster-based types of a given mention are predicted and then, these types are used as features in a ranking model to select the best entity among the candidates. We represent entities at multiple contextual levels and obtain different clusterings (and thus typing models) based on each level. As each clustering breaks the entity space differently, mention typing based on each clustering discriminates the mention differently. When predictions from all typing models are used together, our system achieves better or comparable results based on randomization tests with respect to the state-of-the-art levels on four defacto test sets.