 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIPPER: Robust Data Association without an Initial Guess
Paper and Code

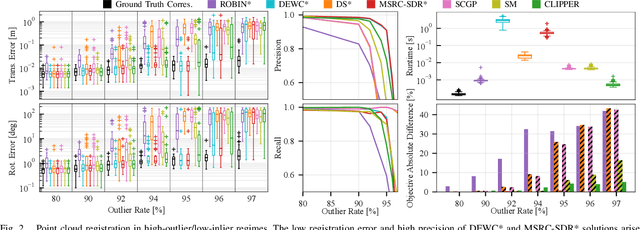
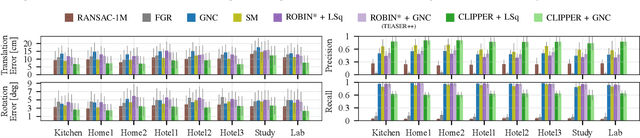
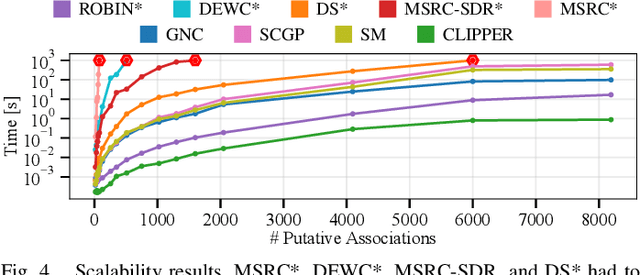
Identifying correspondences in noisy data is a critically important step in estimation processes. When an informative initial estimation guess is available, the data association challenge is less acute; however, the existence of a high-quality initial guess is rare in most contexts. We explore graph-theoretic formulations for data association, which do not require an initial estimation guess. Existing graph-theoretic approaches optimize over unweighted graphs, discarding important consistency information encoded in weighted edges, and frequently attempt to solve NP-hard problems exactly. In contrast, we formulate a new optimization problem that fully leverages weighted graphs and seeks the densest edge-weighted clique. We introduce two relaxations to this problem: a convex semidefinite relaxation which we find to be empirically tight, and a fast first-order algorithm called CLIPPER which frequently arrives at nearly-optimal solutions in milliseconds. When evaluated on point cloud registration problems, our algorithms remain robust up to at least 95% outliers while existing algorithms begin breaking down at 80% outliers. Code is available at https://mit-acl.github.io/clipper.