 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClinical Reading Comprehension with Encoder-Decoder Models Enhanced by Direct Preference Optimization
Paper and Code
Jul 19, 2024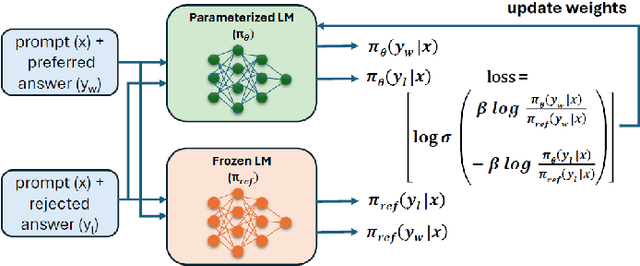
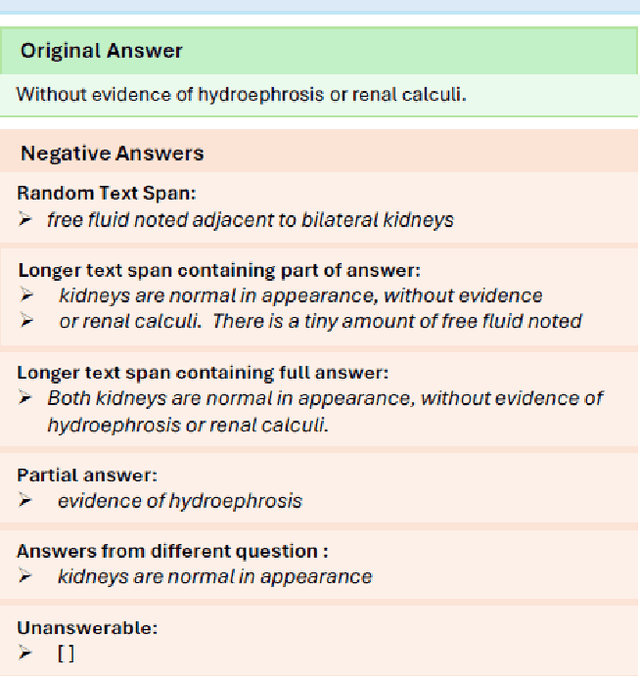
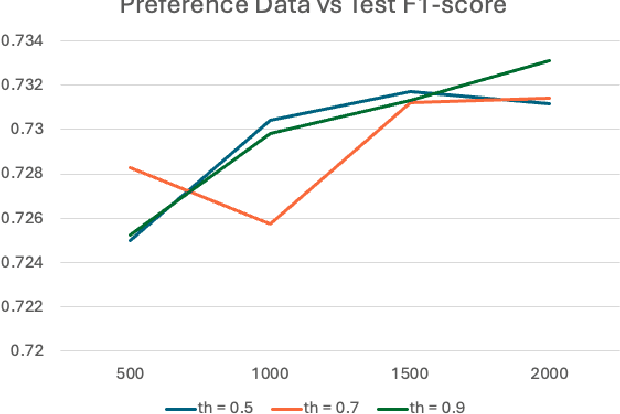
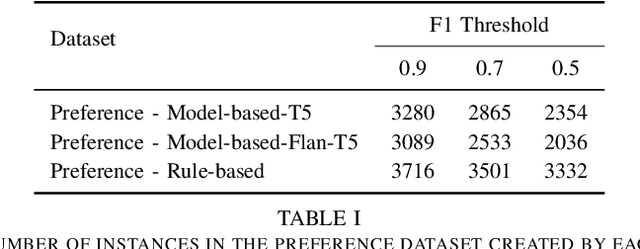
Extractive question answering over clinical text is a crucial need to help deal with the deluge of clinical text generated in hospitals. While encoder models (e.g., BERT) have been popular for this reading comprehension task, recently encoder-decoder models (e.g., T5) are on the rise. There is also the emergence of preference optimization techniques to align decoder-only LLMs with human preferences. In this paper, we combine encoder-decoder models with the direct preference optimization (DPO) method to improve over prior state of the art for the RadQA radiology question answering task by 12-15 F1 points. To the best of our knowledge, this effort is the first to show that DPO method also works for reading comprehension via novel heuristics to generate preference data without human inputs.