 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClear Preferences Leave Traces: Reference Model-Guided Sampling for Preference Learning
Paper and Code
Jan 25, 2025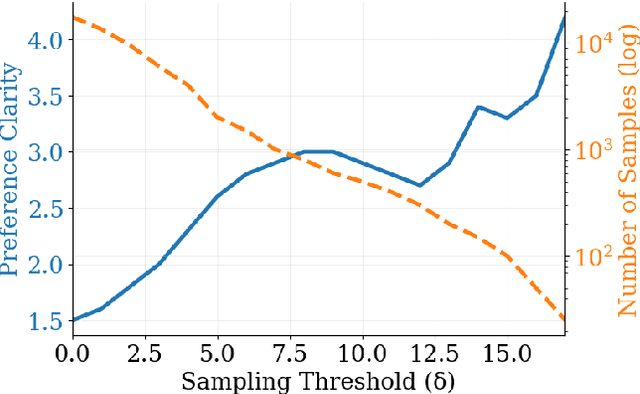
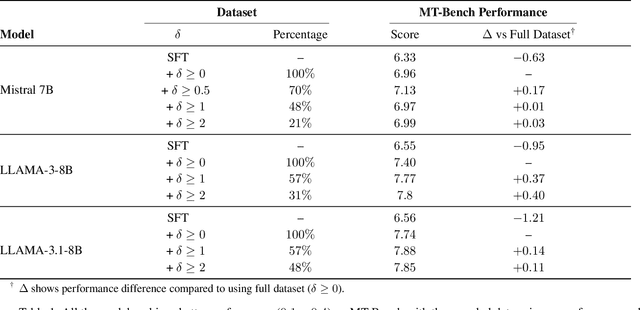
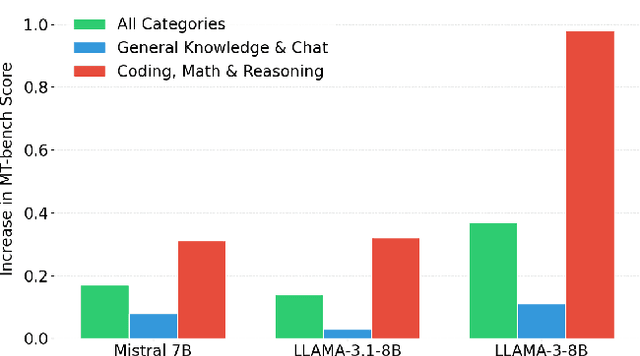
Direct Preference Optimization (DPO) has emerged as a de-facto approach for aligning language models with human preferences. Recent work has shown DPO's effectiveness relies on training data quality. In particular, clear quality differences between preferred and rejected responses enhance learning performance. Current methods for identifying and obtaining such high-quality samples demand additional resources or external models. We discover that reference model probability space naturally detects high-quality training samples. Using this insight, we present a sampling strategy that achieves consistent improvements (+0.1 to +0.4) on MT-Bench while using less than half (30-50%) of the training data. We observe substantial improvements (+0.4 to +0.98) for technical tasks (coding, math, and reasoning) across multiple models and hyperparameter settings.