 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassifying Multilingual User Feedback using Traditional Machine Learning and Deep Learning
Paper and Code
Sep 12, 2019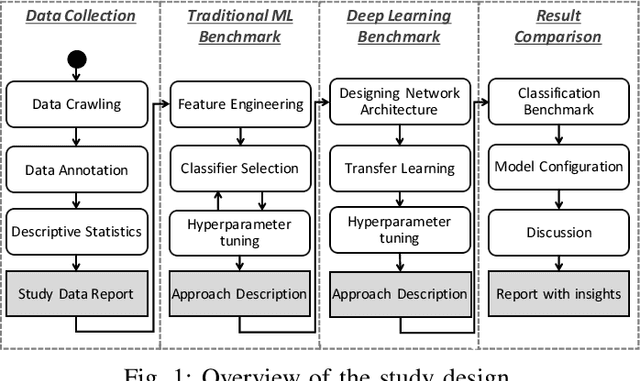
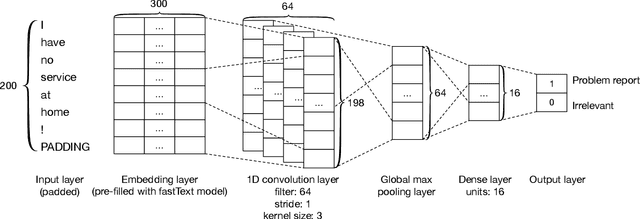
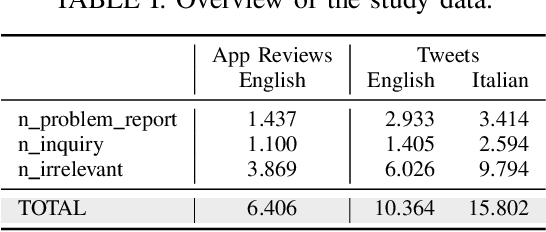
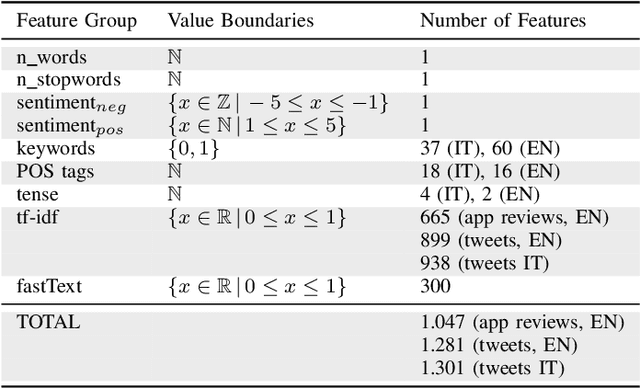
With the rise of social media like Twitter and of software distribution platforms like app stores, users got various ways to express their opinion about software products. Popular software vendors get user feedback thousandfold per day. Research has shown that such feedback contains valuable information for software development teams such as problem reports or feature and support inquires. Since the manual analysis of user feedback is cumbersome and hard to manage many researchers and tool vendors suggested to use automated analyses based on traditional supervised machine learning approaches. In this work, we compare the results of traditional machine learning and deep learning in classifying user feedback in English and Italian into problem reports, inquiries, and irrelevant. Our results show that using traditional machine learning, we can still achieve comparable results to deep learning, although we collected thousands of labels.