 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassification of Infant Crying in Real-World Home Environments Using Deep Learning
Paper and Code
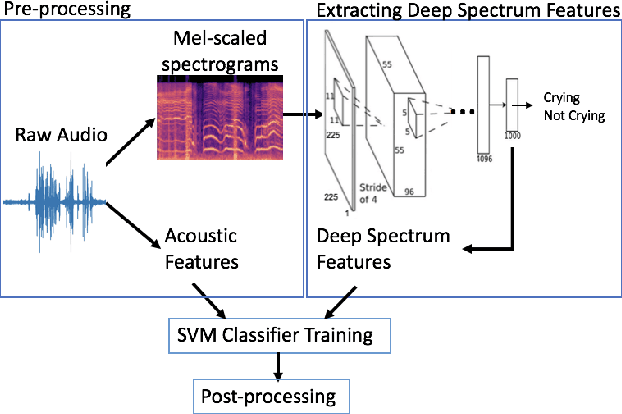
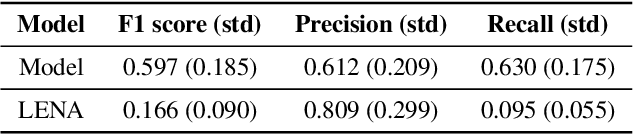
In the domain of social signal processing, audio recognition is a promising avenue for accessing daily behaviors that contribute to health and well-being. However, despite advances in mobile computing and machine learning, audio behavior detection models are largely constrained to data collected in controlled settings, such as call centers. This is problematic as it means their performance is unlikely to generalize to real-world applications. In the current paper, we present a model combining deep spectrum and acoustic features to detect and classify infant distress vocalizations from 24 hour, continuous, raw real-world data collected via a wearable audio recorder. Our model dramatically outperforms infant distress detection models trained and tested on equivalent real-world datasets. In particular, our model has an F1 score of 0.597 relative to F1 scores of 0.166 and 0.26 achieved by state-of-practice and state-of-the-art real-world infant distress classifiers, respectively. We end by discussing what may have facilitated this massive gain in accuracy, including using supervised deep spectrum features and the fact that we collected and annotated a massive dataset of 780 hours of real-world audio data with over 25 hours of labelled distress.