 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassification of Consumer Belief Statements From Social Media
Paper and Code
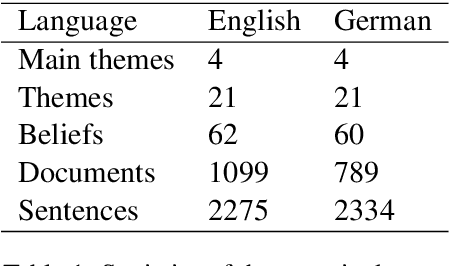
Jun 29, 2021
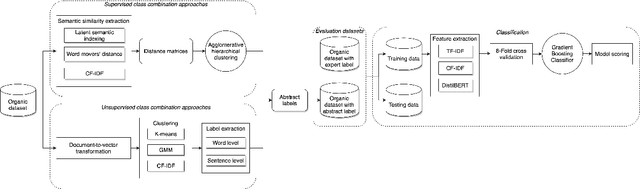

Social media offer plenty of information to perform market research in order to meet the requirements of customers. One way how this research is conducted is that a domain expert gathers and categorizes user-generated content into a complex and fine-grained class structure. In many of such cases, little data meets complex annotations. It is not yet fully understood how this can be leveraged successfully for classification. We examine the classification accuracy of expert labels when used with a) many fine-grained classes and b) few abstract classes. For scenario b) we compare abstract class labels given by the domain expert as baseline and by automatic hierarchical clustering. We compare this to another baseline where the entire class structure is given by a completely unsupervised clustering approach. By doing so, this work can serve as an example of how complex expert annotations are potentially beneficial and can be utilized in the most optimal way for opinion mining in highly specific domains. By exploring across a range of techniques and experiments, we find that automated class abstraction approaches in particular the unsupervised approach performs remarkably well against domain expert baseline on text classification tasks. This has the potential to inspire opinion mining applications in order to support market researchers in practice and to inspire fine-grained automated content analysis on a large scale.