 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassification by estimating the cumulative distribution function for small data
Paper and Code
Oct 13, 2022
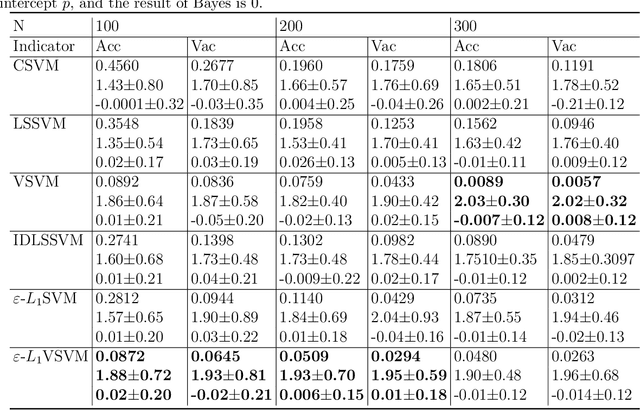
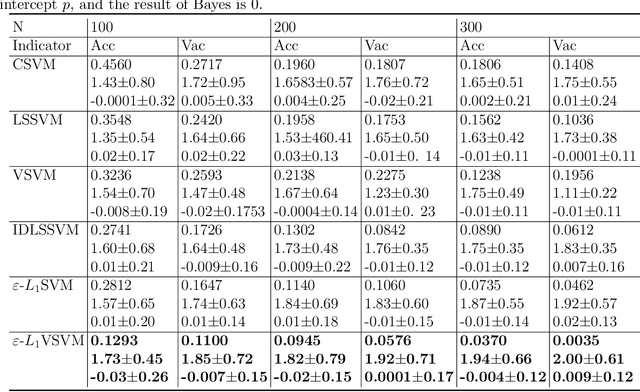
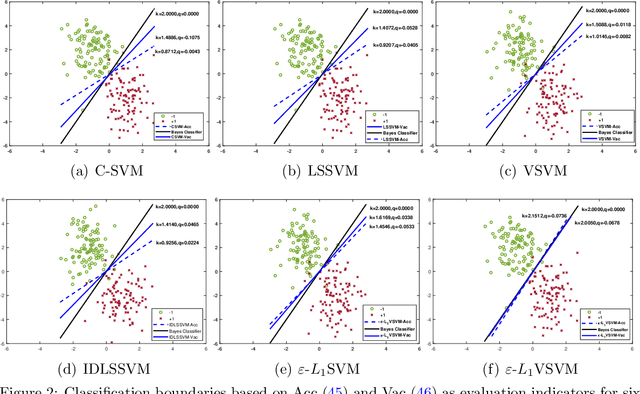
In this paper, we study the classification problem by estimating the conditional probability function of the given data. Different from the traditional expected risk estimation theory on empirical data, we calculate the probability via Fredholm equation, this leads to estimate the distribution of the data. Based on the Fredholm equation, a new expected risk estimation theory by estimating the cumulative distribution function is presented. The main characteristics of the new expected risk estimation is to measure the risk on the distribution of the input space. The corresponding empirical risk estimation is also presented, and an $\varepsilon$-insensitive $L_{1}$ cumulative support vector machines ($\varepsilon$-$L_{1}VSVM$) is proposed by introducing an insensitive loss. It is worth mentioning that the classification models and the classification evaluation indicators based on the new mechanism are different from the traditional one. Experimental results show the effectiveness of the proposed $\varepsilon$-$L_{1}VSVM$ and the corresponding cumulative distribution function indicator on validity and interpretability of small data classification.