 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassification Auto-Encoder based Detector against Diverse Data Poisoning Attacks
Paper and Code
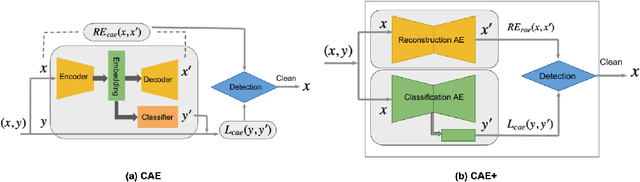
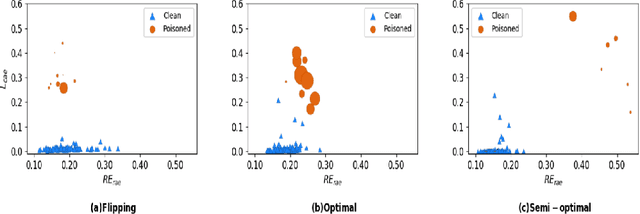
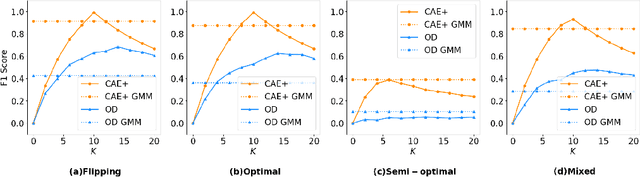
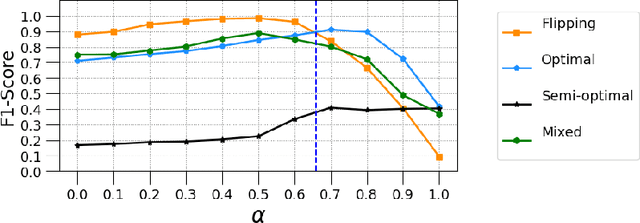
Poisoning attacks are a category of adversarial machine learning threats in which an adversary attempts to subvert the outcome of the machine learning systems by injecting crafted data into training data set, thus increasing the machine learning model's test error. The adversary can tamper with the data feature space, data labels, or both, each leading to a different attack strategy with different strengths. Various detection approaches have recently emerged, each focusing on one attack strategy. The Achilles heel of many of these detection approaches is their dependence on having access to a clean, untampered data set. In this paper, we propose CAE, a Classification Auto-Encoder based detector against diverse poisoned data. CAE can detect all forms of poisoning attacks using a combination of reconstruction and classification errors without having any prior knowledge of the attack strategy. We show that an enhanced version of CAE (called CAE+) does not have to employ a clean data set to train the defense model. Our experimental results on three real datasets MNIST, Fashion-MNIST and CIFAR demonstrate that our proposed method can maintain its functionality under up to 30% contaminated data and help the defended SVM classifier to regain its best accuracy.