 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClaim-Dissector: An Interpretable Fact-Checking System with Joint Re-ranking and Veracity Prediction
Paper and Code
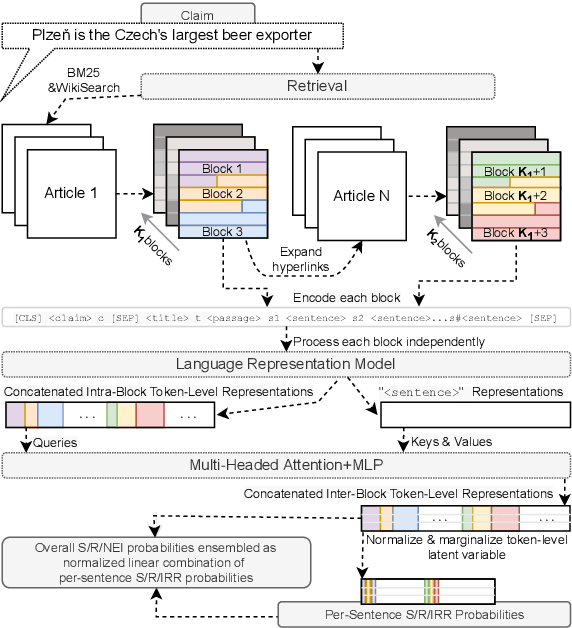



We present Claim-Dissector: a novel latent variable model for fact-checking and fact-analysis, which given a claim and a set of retrieved provenances allows learning jointly: (i) what are the relevant provenances to this claim (ii) what is the veracity of this claim. We propose to disentangle the per-provenance relevance probability and its contribution to the final veracity probability in an interpretable way - the final veracity probability is proportional to a linear ensemble of per-provenance relevance probabilities. This way, it can be clearly identified the relevance of which sources contributes to what extent towards the final probability. We show that our system achieves state-of-the-art results on FEVER dataset comparable to two-stage systems typically used in traditional fact-checking pipelines, while it often uses significantly less parameters and computation. Our analysis shows that proposed approach further allows to learn not just which provenances are relevant, but also which provenances lead to supporting and which toward denying the claim, without direct supervision. This not only adds interpretability, but also allows to detect claims with conflicting evidence automatically. Furthermore, we study whether our model can learn fine-grained relevance cues while using coarse-grained supervision. We show that our model can achieve competitive sentence-recall while using only paragraph-level relevance supervision. Finally, traversing towards the finest granularity of relevance, we show that our framework is capable of identifying relevance at the token-level. To do this, we present a new benchmark focusing on token-level interpretability - humans annotate tokens in relevant provenances they considered essential when making their judgement. Then we measure how similar are these annotations to tokens our model is focusing on. Our code, and dataset will be released online.