 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCheckworthiness in Automatic Claim Detection Models: Definitions and Analysis of Datasets
Paper and Code
Aug 20, 2020
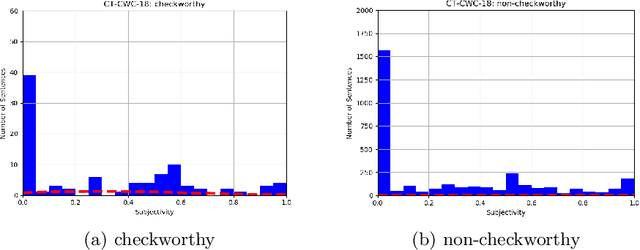
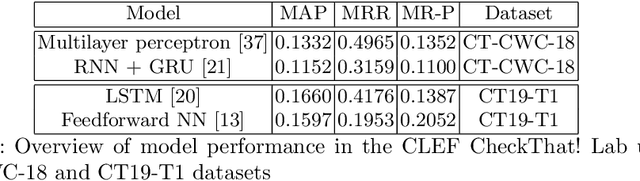

Public, professional and academic interest in automated fact-checking has drastically increased over the past decade, with many aiming to automate one of the first steps in a fact-check procedure: the selection of so-called checkworthy claims. However, there is little agreement on the definition and characteristics of checkworthiness among fact-checkers, which is consequently reflected in the datasets used for training and testing checkworthy claim detection models. After elaborate analysis of checkworthy claim selection procedures in fact-check organisations and analysis of state-of-the-art claim detection datasets, checkworthiness is defined as the concept of having a spatiotemporal and context-dependent worth and need to have the correctness of the objectivity it conveys verified. This is irrespective of the claim's perceived veracity judgement by an individual based on prior knowledge and beliefs. Concerning the characteristics of current datasets, it is argued that the data is not only highly imbalanced and noisy, but also too limited in scope and language. Furthermore, we believe that the subjective concept of checkworthiness might not be a suitable filter for claim detection.