 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing Transactional Databases for Frequent Itemset Mining
Paper and Code
Nov 09, 2020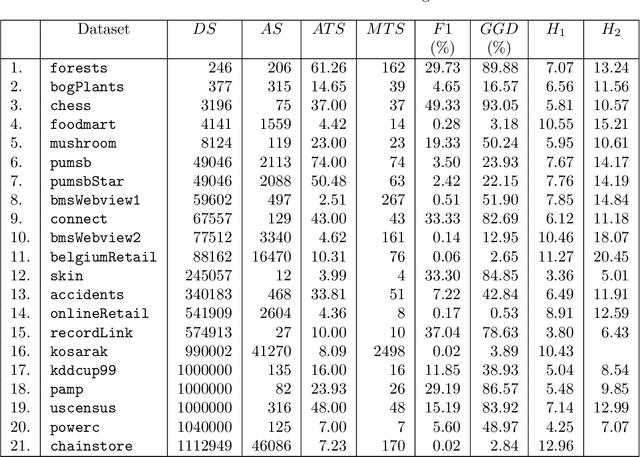
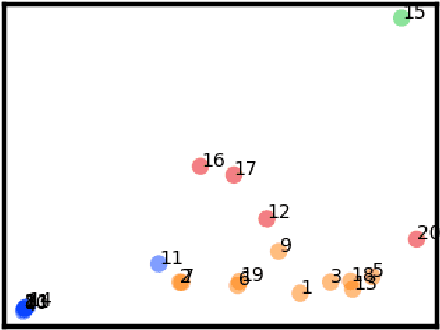
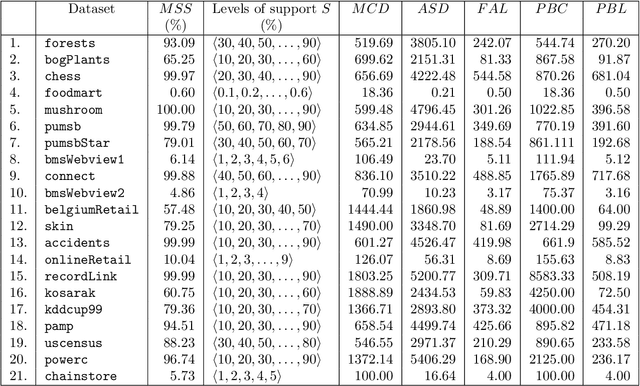
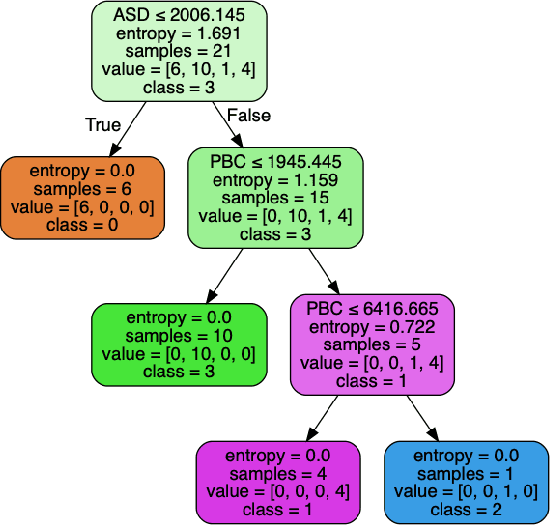
This paper presents a study of the characteristics of transactional databases used in frequent itemset mining. Such characterizations have typically been used to benchmark and understand the data mining algorithms working on these databases. The aim of our study is to give a picture of how diverse and representative these benchmarking databases are, both in general but also in the context of particular empirical studies found in the literature. Our proposed list of metrics contains many of the existing metrics found in the literature, as well as new ones. Our study shows that our list of metrics is able to capture much of the datasets' inner complexity and thus provides a good basis for the characterization of transactional datasets. Finally, we provide a set of representative datasets based on our characterization that may be used as a benchmark safely.