 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChannel-Recurrent Autoencoding for Image Modeling
Paper and Code
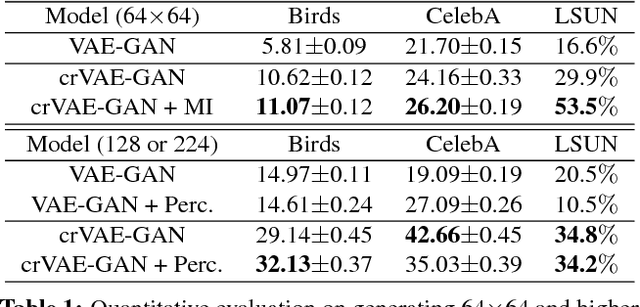
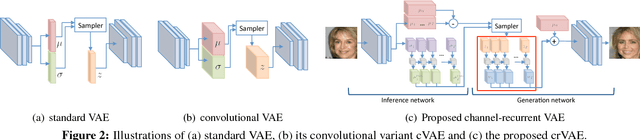


Despite recent successes in synthesizing faces and bedrooms, existing generative models struggle to capture more complex image types, potentially due to the oversimplification of their latent space constructions. To tackle this issue, building on Variational Autoencoders (VAEs), we integrate recurrent connections across channels to both inference and generation steps, allowing the high-level features to be captured in global-to-local, coarse-to-fine manners. Combined with adversarial loss, our channel-recurrent VAE-GAN (crVAE-GAN) outperforms VAE-GAN in generating a diverse spectrum of high resolution images while maintaining the same level of computational efficacy. Our model produces interpretable and expressive latent representations to benefit downstream tasks such as image completion. Moreover, we propose two novel regularizations, namely the KL objective weighting scheme over time steps and mutual information maximization between transformed latent variables and the outputs, to enhance the training.