 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChain-of-Thought Reasoning is a Policy Improvement Operator
Paper and Code
Sep 15, 2023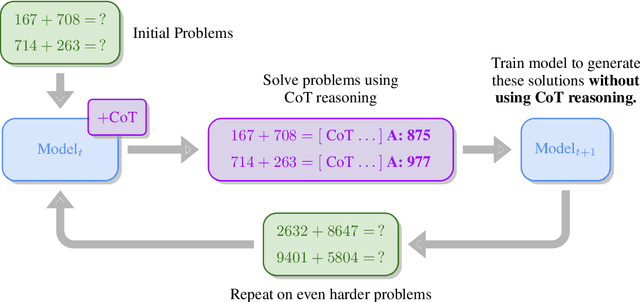



Large language models have astounded the world with fascinating new capabilities. However, they currently lack the ability to teach themselves new skills, relying instead on being trained on large amounts of human-generated data. We introduce SECToR (Self-Education via Chain-of-Thought Reasoning), a proof-of-concept demonstration that language models can successfully teach themselves new skills using chain-of-thought reasoning. Inspired by previous work in both reinforcement learning (Silver et al., 2017) and human cognition (Kahneman, 2011), SECToR first uses chain-of-thought reasoning to slowly think its way through problems. SECToR then fine-tunes the model to generate those same answers, this time without using chain-of-thought reasoning. Language models trained via SECToR autonomously learn to add up to 29-digit numbers without any access to any ground truth examples beyond an initial supervised fine-tuning phase consisting only of numbers with 6 or fewer digits. Our central hypothesis is that chain-of-thought reasoning can act as a policy improvement operator, analogously to how Monte-Carlo Tree Search is used in AlphaZero. We hope that this research can lead to new directions in which language models can learn to teach themselves without the need for human demonstrations.