 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCGaP: Continuous Growth and Pruning for Efficient Deep Learning
Paper and Code
May 29, 2019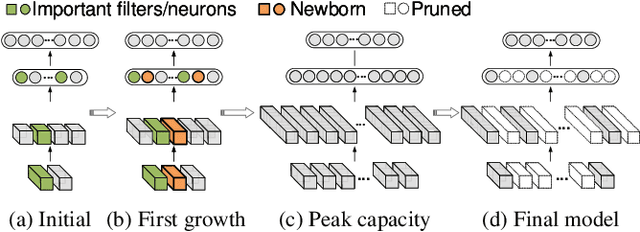

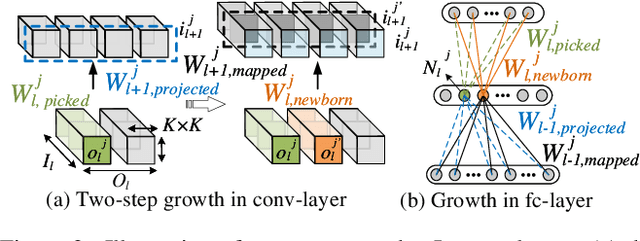
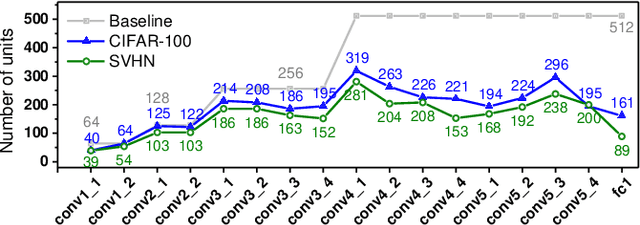
Today a canonical approach to reduce the computation cost of Deep Neural Networks (DNNs) is to pre-define an over-parameterized model before training to guarantee the learning capacity, and then prune unimportant learning units (filters and neurons) during training to improve model compactness. We argue it is unnecessary to introduce redundancy at the beginning of the training but then reduce redundancy for the ultimate inference model. In this paper, we propose a Continuous Growth and Pruning (CGaP) scheme to minimize the redundancy from the beginning. CGaP starts the training from a small network seed, then expands the model continuously by reinforcing important learning units, and finally prunes the network to obtain a compact and accurate model. As the growth phase favors important learning units, CGaP provides a clear learning purpose to the pruning phase. Experimental results on representative datasets and DNN architectures demonstrate that CGaP outperforms previous pruning-only approaches that deal with pre-defined structures. For VGG-19 on CIFAR-100 and SVHN datasets, CGaP reduces the number of parameters by 78.9% and 85.8%, FLOPs by 53.2% and 74.2%, respectively; For ResNet-110 On CIFAR-10, CGaP reduces 64.0% number of parameters and 63.3% FLOPs.