 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCause and Effect: Concept-based Explanation of Neural Networks
Paper and Code
May 14, 2021
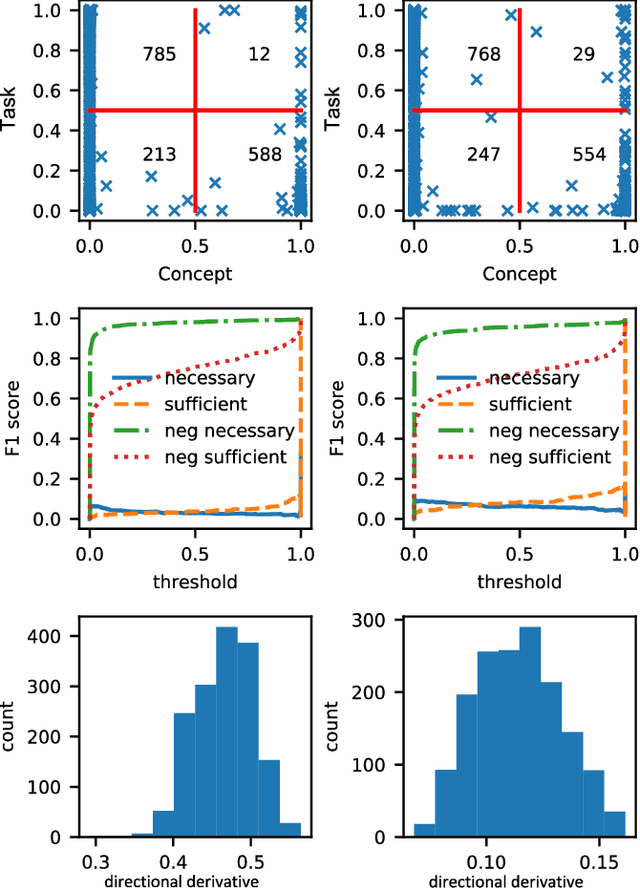


In many scenarios, human decisions are explained based on some high-level concepts. In this work, we take a step in the interpretability of neural networks by examining their internal representation or neuron's activations against concepts. A concept is characterized by a set of samples that have specific features in common. We propose a framework to check the existence of a causal relationship between a concept (or its negation) and task classes. While the previous methods focus on the importance of a concept to a task class, we go further and introduce four measures to quantitatively determine the order of causality. Through experiments, we demonstrate the effectiveness of the proposed method in explaining the relationship between a concept and the predictive behaviour of a neural network.