 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal discovery for observational sciences using supervised machine learning
Paper and Code
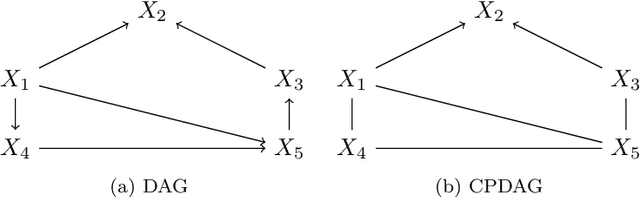
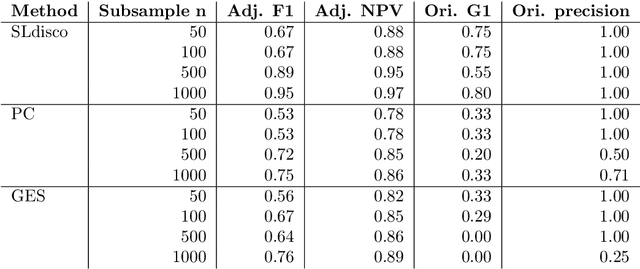
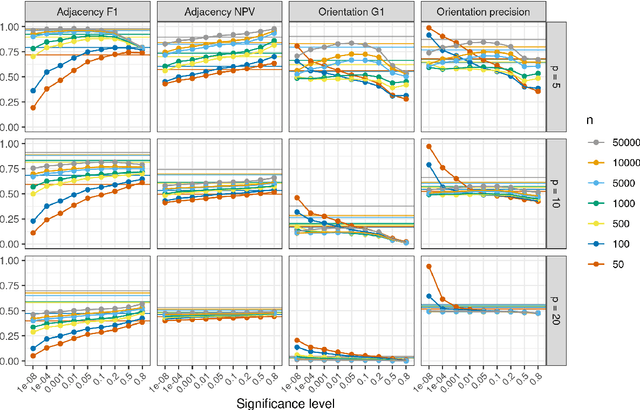
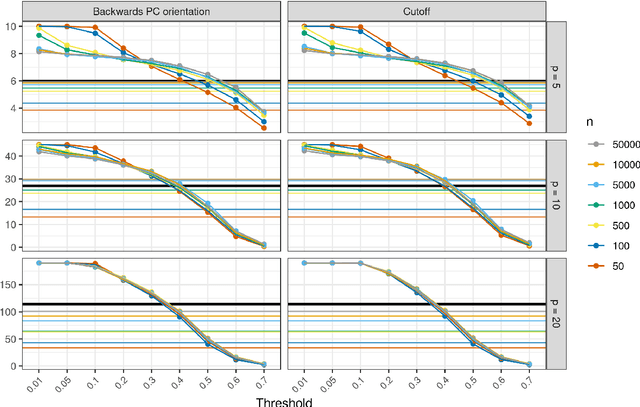
Causal inference can estimate causal effects, but unless data are collected experimentally, statistical analyses must rely on pre-specified causal models. Causal discovery algorithms are empirical methods for constructing such causal models from data. Several asymptotically correct methods already exist, but they generally struggle on smaller samples. Moreover, most methods focus on very sparse causal models, which may not always be a realistic representation of real-life data generating mechanisms. Finally, while causal relationships suggested by the methods often hold true, their claims about causal non-relatedness have high error rates. This non-conservative error tradeoff is not ideal for observational sciences, where the resulting model is directly used to inform causal inference: A causal model with many missing causal relations entails too strong assumptions and may lead to biased effect estimates. We propose a new causal discovery method that addresses these three shortcomings: Supervised learning discovery (SLdisco). SLdisco uses supervised machine learning to obtain a mapping from observational data to equivalence classes of causal models. We evaluate SLdisco in a large simulation study based on Gaussian data and we consider several choices of model size and sample size. We find that SLdisco is more conservative, only moderately less informative and less sensitive towards sample size than existing procedures. We furthermore provide a real epidemiological data application. We use random subsampling to investigate real data performance on small samples and again find that SLdisco is less sensitive towards sample size and hence seems to better utilize the information available in small datasets.