 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapturing Pertinent Symbolic Features for Enhanced Content-Based Misinformation Detection
Paper and Code



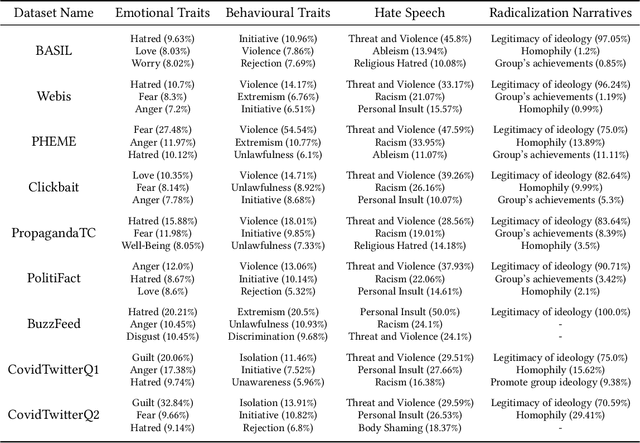
Preventing the spread of misinformation is challenging. The detection of misleading content presents a significant hurdle due to its extreme linguistic and domain variability. Content-based models have managed to identify deceptive language by learning representations from textual data such as social media posts and web articles. However, aggregating representative samples of this heterogeneous phenomenon and implementing effective real-world applications is still elusive. Based on analytical work on the language of misinformation, this paper analyzes the linguistic attributes that characterize this phenomenon and how representative of such features some of the most popular misinformation datasets are. We demonstrate that the appropriate use of pertinent symbolic knowledge in combination with neural language models is helpful in detecting misleading content. Our results achieve state-of-the-art performance in misinformation datasets across the board, showing that our approach offers a valid and robust alternative to multi-task transfer learning without requiring any additional training data. Furthermore, our results show evidence that structured knowledge can provide the extra boost required to address a complex and unpredictable real-world problem like misinformation detection, not only in terms of accuracy but also time efficiency and resource utilization.