 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapsuleVOS: Semi-Supervised Video Object Segmentation Using Capsule Routing
Paper and Code
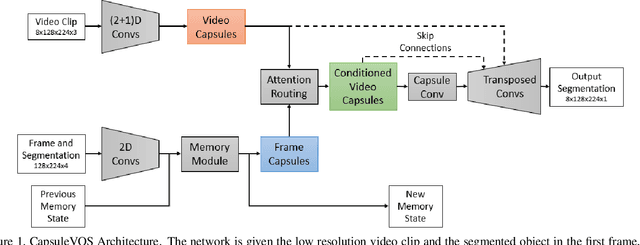

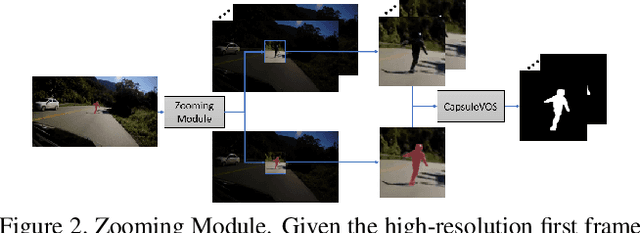
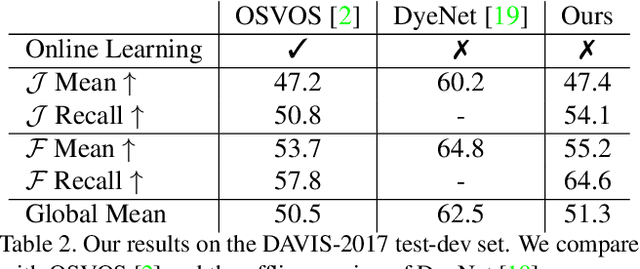
In this work we propose a capsule-based approach for semi-supervised video object segmentation. Current video object segmentation methods are frame-based and often require optical flow to capture temporal consistency across frames which can be difficult to compute. To this end, we propose a video based capsule network, CapsuleVOS, which can segment several frames at once conditioned on a reference frame and segmentation mask. This conditioning is performed through a novel routing algorithm for attention-based efficient capsule selection. We address two challenging issues in video object segmentation: 1) segmentation of small objects and 2) occlusion of objects across time. The issue of segmenting small objects is addressed with a zooming module which allows the network to process small spatial regions of the video. Apart from this, the framework utilizes a novel memory module based on recurrent networks which helps in tracking objects when they move out of frame or are occluded. The network is trained end-to-end and we demonstrate its effectiveness on two benchmark video object segmentation datasets; it outperforms current offline approaches on the Youtube-VOS dataset while having a run-time that is almost twice as fast as competing methods. The code is publicly available at https://github.com/KevinDuarte/CapsuleVOS.