Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapsule networks for low-data transfer learning
Paper and Code
Apr 26, 2018
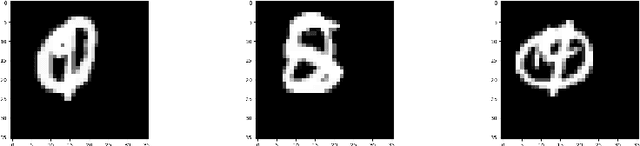
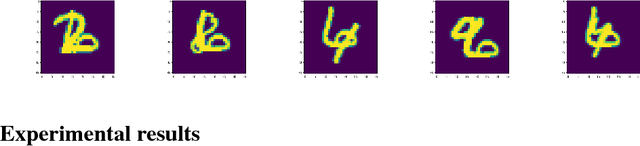

We propose a capsule network-based architecture for generalizing learning to new data with few examples. Using both generative and non-generative capsule networks with intermediate routing, we are able to generalize to new information over 25 times faster than a similar convolutional neural network. We train the networks on the multiMNIST dataset lacking one digit. After the networks reach their maximum accuracy, we inject 1-100 examples of the missing digit into the training set, and measure the number of batches needed to return to a comparable level of accuracy. We then discuss the improvement in low-data transfer learning that capsule networks bring, and propose future directions for capsule research.
* 11 pages, 10 figures
View paper on