 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan We Optimize Deep RL Policy Weights as Trajectory Modeling?
Paper and Code
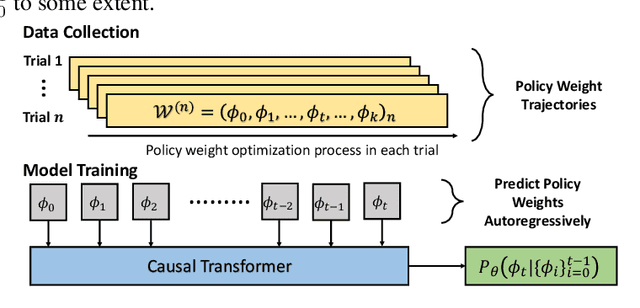
Learning the optimal policy from a random network initialization is the theme of deep Reinforcement Learning (RL). As the scale of DRL training increases, treating DRL policy network weights as a new data modality and exploring the potential becomes appealing and possible. In this work, we focus on the policy learning path in deep RL, represented by the trajectory of network weights of historical policies, which reflects the evolvement of the policy learning process. Taking the idea of trajectory modeling with Transformer, we propose Transformer as Implicit Policy Learner (TIPL), which processes policy network weights in an autoregressive manner. We collect the policy learning path data by running independent RL training trials, with which we then train our TIPL model. In the experiments, we demonstrate that TIPL is able to fit the implicit dynamics of policy learning and perform the optimization of policy network by inference.