 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan We Do Better Than Random Start? The Power of Data Outsourcing
Paper and Code
May 17, 2022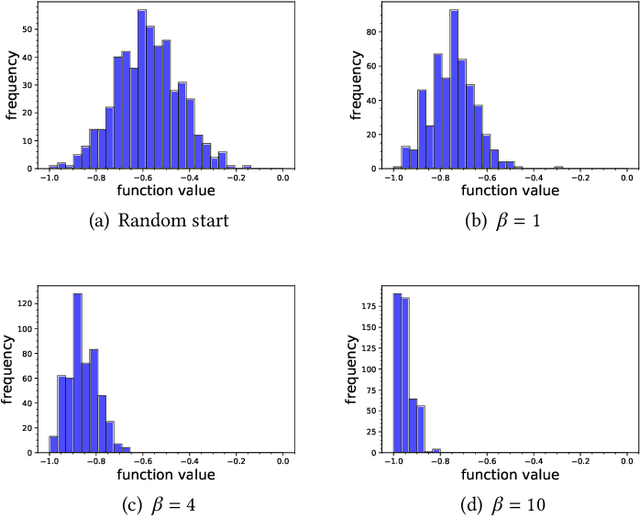
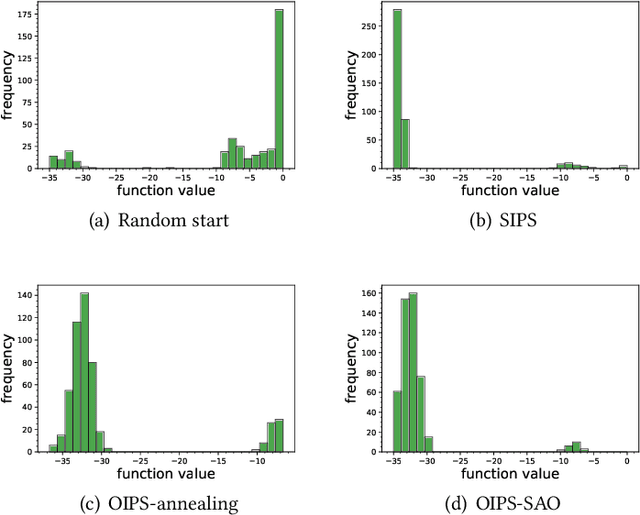
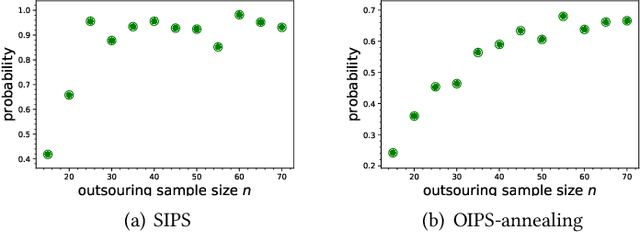
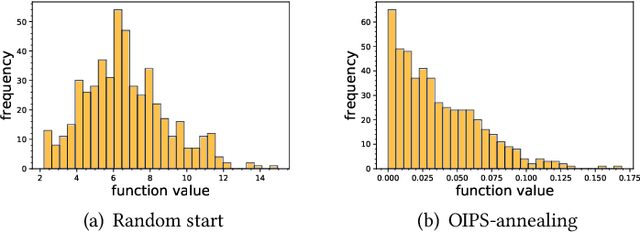
Many organizations have access to abundant data but lack the computational power to process the data. While they can outsource the computational task to other facilities, there are various constraints on the amount of data that can be shared. It is natural to ask what can data outsourcing accomplish under such constraints. We address this question from a machine learning perspective. When training a model with optimization algorithms, the quality of the results often relies heavily on the points where the algorithms are initialized. Random start is one of the most popular methods to tackle this issue, but it can be computationally expensive and not feasible for organizations lacking computing resources. Based on three different scenarios, we propose simulation-based algorithms that can utilize a small amount of outsourced data to find good initial points accordingly. Under suitable regularity conditions, we provide theoretical guarantees showing the algorithms can find good initial points with high probability. We also conduct numerical experiments to demonstrate that our algorithms perform significantly better than the random start approach.