 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Pretext-Based Self-Supervised Learning Be Boosted by Downstream Data? A Theoretical Analysis
Paper and Code
Mar 05, 2021
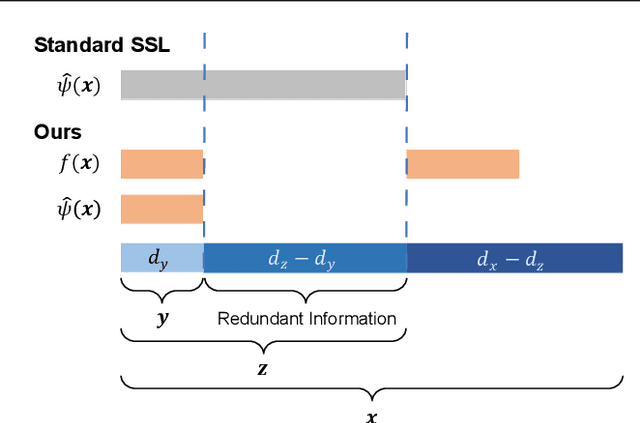

Pretext-based self-supervised learning aims to learn the semantic representation via a handcrafted pretext task over unlabeled data and then use the learned representation for downstream prediction tasks. \citet{lee2020predicting} prove that pretext-based self-supervised learning can effectively reduce the sample complexity of downstream tasks under Conditional Independence (CI) between the components of the pretext task conditional on the downstream label. However, the CI condition rarely holds in practice, and the downstream sample complexity will get much worse if the CI condition does not hold. In this paper, we explore the idea of applying a learnable function to the input to make the CI condition hold. In particular, we first rigorously formulate the criteria that the function needs to satisfy. We then design an ingenious loss function for learning such a function and prove that the function minimizing the proposed loss satisfies the above criteria. We theoretically study the number of labeled data required, and give a model-free lower bound showing that taking limited downstream data will hurt the performance of self-supervised learning. Furthermore, we take the model structure into account and give a model-dependent lower bound, which gets higher when the model capacity gets larger. Moreover, we conduct several numerical experiments to verify our theoretical results.