 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibration of P-values for calibration and for deviation of a subpopulation from the full population
Paper and Code
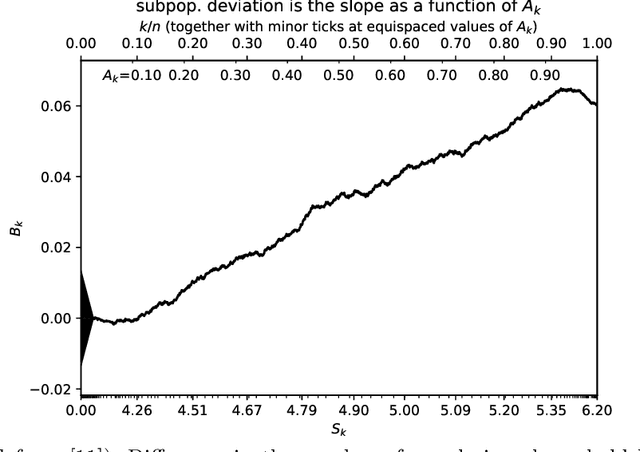
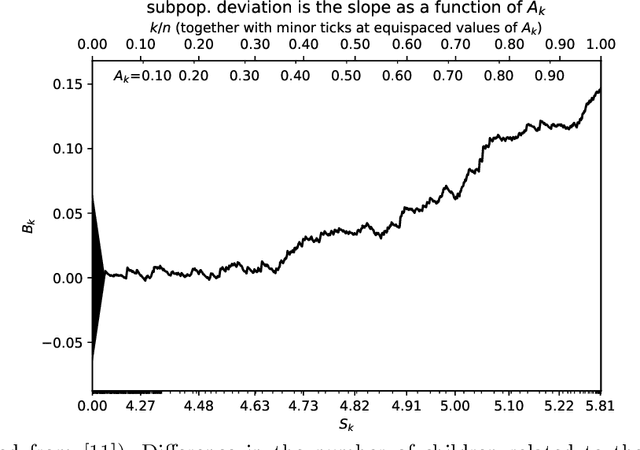
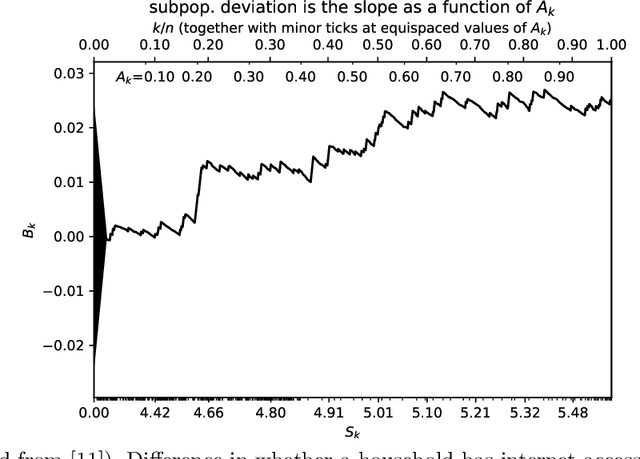
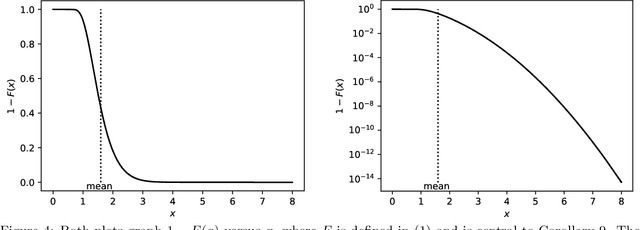
The author's recent research papers, "Cumulative deviation of a subpopulation from the full population" and "A graphical method of cumulative differences between two subpopulations" (both published in volume 8 of Springer's open-access "Journal of Big Data" during 2021), propose graphical methods and summary statistics, without extensively calibrating formal significance tests. The summary metrics and methods can measure the calibration of probabilistic predictions and can assess differences in responses between a subpopulation and the full population while controlling for a covariate or score via conditioning on it. These recently published papers construct significance tests based on the scalar summary statistics, but only sketch how to calibrate the attained significance levels (also known as "P-values") for the tests. The present article reviews and synthesizes work spanning many decades in order to detail how to calibrate the P-values. The present paper presents computationally efficient, easily implemented numerical methods for evaluating properly calibrated P-values, together with rigorous mathematical proofs guaranteeing their accuracy, and illustrates and validates the methods with open-source software and numerical examples.