Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibrating for Class Weights by Modeling Machine Learning
Paper and Code
May 10, 2022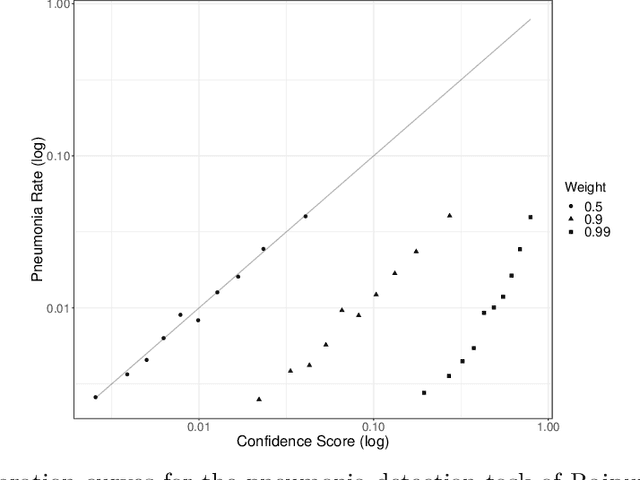

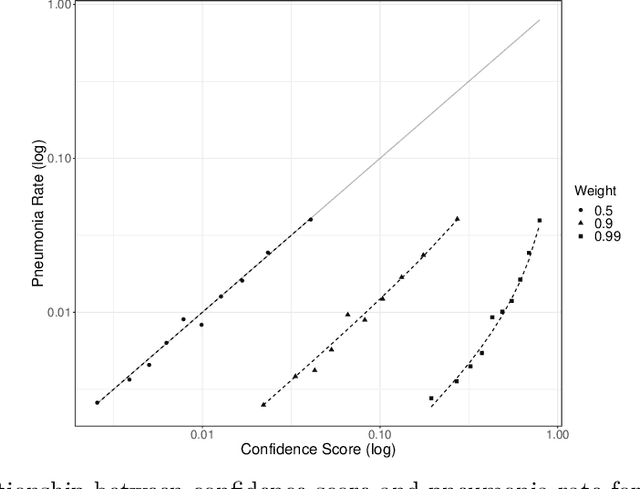

A much studied issue is the extent to which the confidence scores provided by machine learning algorithms are calibrated to ground truth probabilities. Our starting point is that calibration is seemingly incompatible with class weighting, a technique often employed when one class is less common (class imbalance) or with the hope of achieving some external objective (cost-sensitive learning). We provide a model-based explanation for this incompatibility and use our anthropomorphic model to generate a simple method of recovering likelihoods from an algorithm that is miscalibrated due to class weighting. We validate this approach in the binary pneumonia detection task of Rajpurkar, Irvin, Zhu, et al. (2017).
* 12 pages, 4 figures
View paper on