 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAGAN: Text-To-Image Generation with Combined Attention GANs
Paper and Code

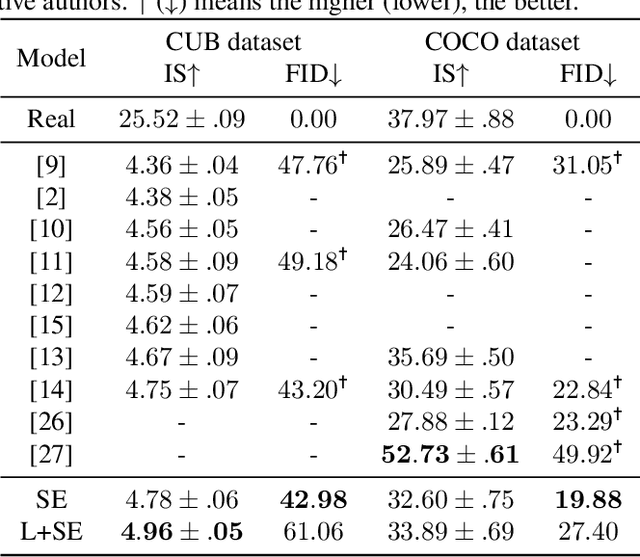


Generating images according to natural language descriptions is a challenging task. In this work, we propose the Combined Attention Generative Adversarial Network (CAGAN) to generate photo-realistic images according to textual descriptions. The proposed CAGAN utilises two attention models: word attention to draw different sub-regions conditioned on related words; and squeeze-and-excitation attention to capture non-linear interaction among channels. With spectral normalisation to stabilise training, our proposed CAGAN improves the state of the art on the IS and FID on the CUB dataset and the FID on the more challenging COCO dataset. Furthermore, we demonstrate that judging a model by a single evaluation metric can be misleading by developing an additional model adding local self-attention which scores a higher IS, outperforming the state of the art on the CUB dataset, but generates unrealistic images through feature repetition.