 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeByzShield: An Efficient and Robust System for Distributed Training
Paper and Code

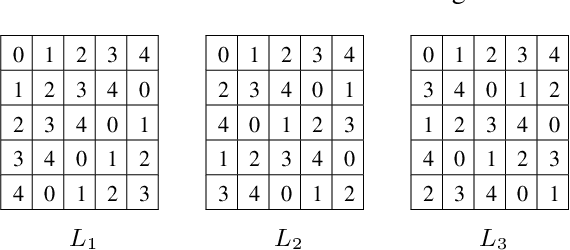
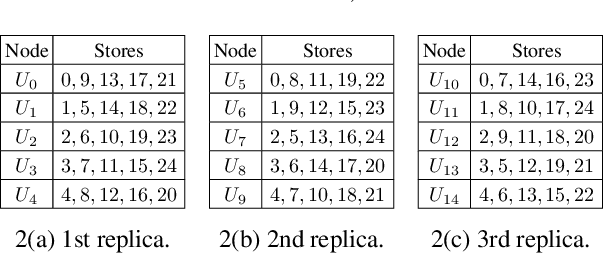
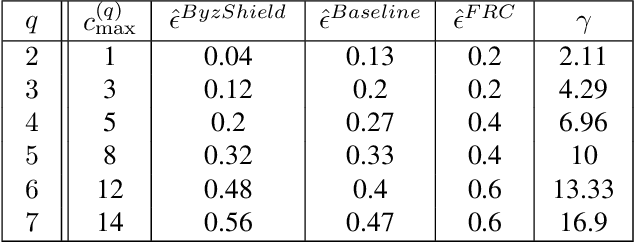
Training of large scale models on distributed clusters is a critical component of the machine learning pipeline. However, this training can easily be made to fail if some workers behave in an adversarial (Byzantine) fashion whereby they return arbitrary results to the parameter server (PS). A plethora of existing papers consider a variety of attack models and propose robust aggregation and/or computational redundancy to alleviate the effects of these attacks. In this work we consider an omniscient attack model where the adversary has full knowledge about the gradient computation assignments of the workers and can choose to attack (up to) any q out of n worker nodes to induce maximal damage. Our redundancy-based method ByzShield leverages the properties of bipartite expander graphs for the assignment of tasks to workers; this helps to effectively mitigate the effect of the Byzantine behavior. Specifically, we demonstrate an upper bound on the worst case fraction of corrupted gradients based on the eigenvalues of our constructions which are based on mutually orthogonal Latin squares and Ramanujan graphs. Our numerical experiments indicate over a 36% reduction on average in the fraction of corrupted gradients compared to the state of the art. Likewise, our experiments on training followed by image classification on the CIFAR-10 dataset show that ByzShield has on average a 20% advantage in accuracy under the most sophisticated attacks. ByzShield also tolerates a much larger fraction of adversarial nodes compared to prior work.