 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding a 3-Player Mahjong AI using Deep Reinforcement Learning
Paper and Code
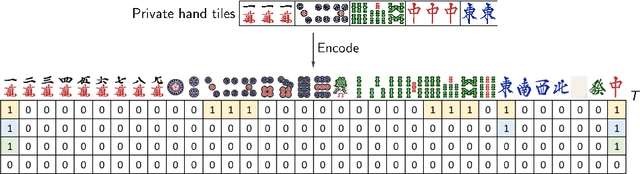
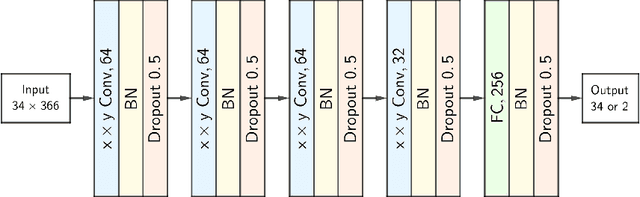
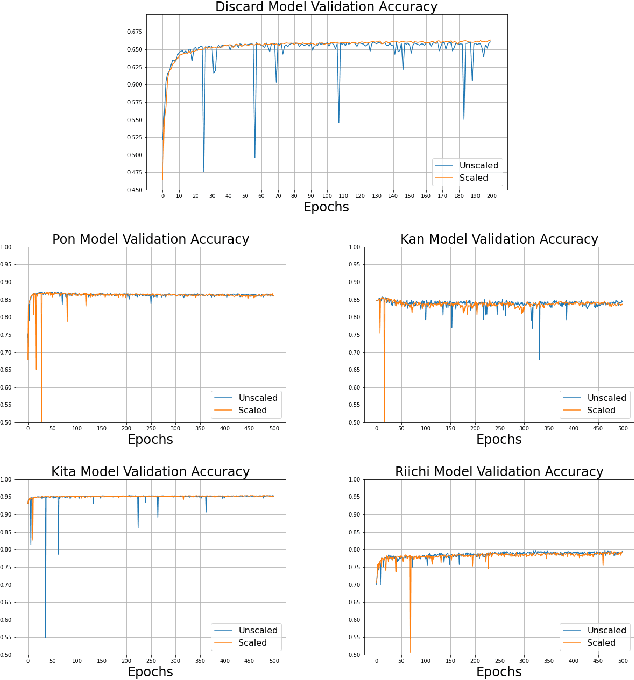
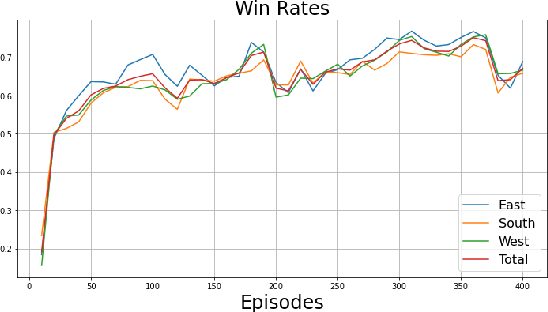
Mahjong is a popular multi-player imperfect-information game developed in China in the late 19th-century, with some very challenging features for AI research. Sanma, being a 3-player variant of the Japanese Riichi Mahjong, possesses unique characteristics including fewer tiles and, consequently, a more aggressive playing style. It is thus challenging and of great research interest in its own right, but has not yet been explored. In this paper, we present Meowjong, an AI for Sanma using deep reinforcement learning. We define an informative and compact 2-dimensional data structure for encoding the observable information in a Sanma game. We pre-train 5 convolutional neural networks (CNNs) for Sanma's 5 actions -- discard, Pon, Kan, Kita and Riichi, and enhance the major action's model, namely the discard model, via self-play reinforcement learning using the Monte Carlo policy gradient method. Meowjong's models achieve test accuracies comparable with AIs for 4-player Mahjong through supervised learning, and gain a significant further enhancement from reinforcement learning. Being the first ever AI in Sanma, we claim that Meowjong stands as a state-of-the-art in this game.