 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBT-Unet: A self-supervised learning framework for biomedical image segmentation using Barlow Twins with U-Net models
Paper and Code
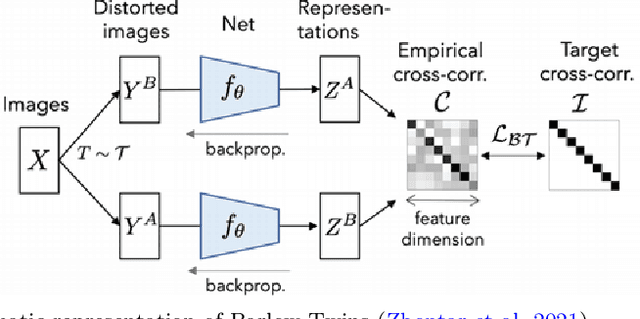
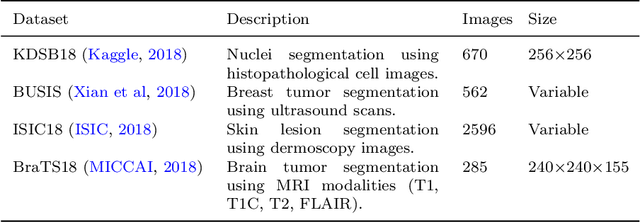


Deep learning has brought the most profound contribution towards biomedical image segmentation to automate the process of delineation in medical imaging. To accomplish such task, the models are required to be trained using huge amount of annotated or labelled data that highlights the region of interest with a binary mask. However, efficient generation of the annotations for such huge data requires expert biomedical analysts and extensive manual effort. It is a tedious and expensive task, while also being vulnerable to human error. To address this problem, a self-supervised learning framework, BT-Unet is proposed that uses the Barlow Twins approach to pre-train the encoder of a U-Net model via redundancy reduction in an unsupervised manner to learn data representation. Later, complete network is fine-tuned to perform actual segmentation. The BT-Unet framework can be trained with a limited number of annotated samples while having high number of unannotated samples, which is mostly the case in real-world problems. This framework is validated over multiple U-Net models over diverse datasets by generating scenarios of a limited number of labelled samples using standard evaluation metrics. With exhaustive experiment trials, it is observed that the BT-Unet framework enhances the performance of the U-Net models with significant margin under such circumstances.