 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrown University at TREC Deep Learning 2019
Paper and Code
Sep 08, 2020
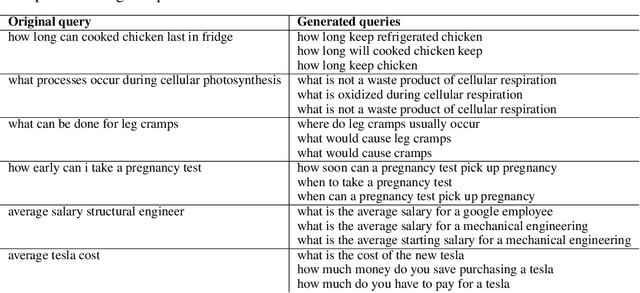

This paper describes Brown University's submission to the TREC 2019 Deep Learning track. We followed a 2-phase method for producing a ranking of passages for a given input query: In the the first phase, the user's query is expanded by appending 3 queries generated by a transformer model which was trained to rephrase an input query into semantically similar queries. The expanded query can exhibit greater similarity in surface form and vocabulary overlap with the passages of interest and can therefore serve as enriched input to any downstream information retrieval method. In the second phase, we use a BERT-based model pre-trained for language modeling but fine-tuned for query - document relevance prediction to compute relevance scores for a set of 1000 candidate passages per query and subsequently obtain a ranking of passages by sorting them based on the predicted relevance scores. According to the results published in the official Overview of the TREC Deep Learning Track 2019, our team ranked 3rd in the passage retrieval task (including full ranking and re-ranking), and 2nd when considering only re-ranking submissions.