 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBROADCAST: Reducing Both Stochastic and Compression Noise to Robustify Communication-Efficient Federated Learning
Paper and Code
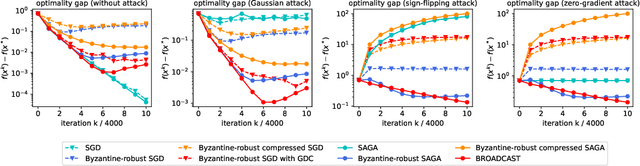
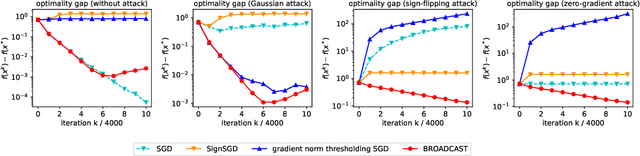
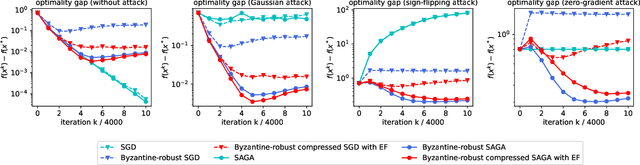
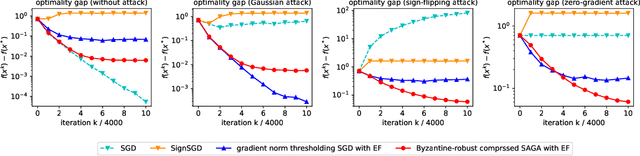
Communication between workers and the master node to collect local stochastic gradients is a key bottleneck in a large-scale federated learning system. Various recent works have proposed to compress the local stochastic gradients to mitigate the communication overhead. However, robustness to malicious attacks is rarely considered in such a setting. In this work, we investigate the problem of Byzantine-robust federated learning with compression, where the attacks from Byzantine workers can be arbitrarily malicious. We point out that a vanilla combination of compressed stochastic gradient descent (SGD) and geometric median-based robust aggregation suffers from both stochastic and compression noise in the presence of Byzantine attacks. In light of this observation, we propose to jointly reduce the stochastic and compression noise so as to improve the Byzantine-robustness. For the stochastic noise, we adopt the stochastic average gradient algorithm (SAGA) to gradually eliminate the inner variations of regular workers. For the compression noise, we apply the gradient difference compression and achieve compression for free. We theoretically prove that the proposed algorithm reaches a neighborhood of the optimal solution at a linear convergence rate, and the asymptotic learning error is in the same order as that of the state-of-the-art uncompressed method. Finally, numerical experiments demonstrate effectiveness of the proposed method.