 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Topic, Domain, and Language Shifts: An Evaluation of Comprehensive Out-of-Distribution Scenarios
Paper and Code
Sep 15, 2023
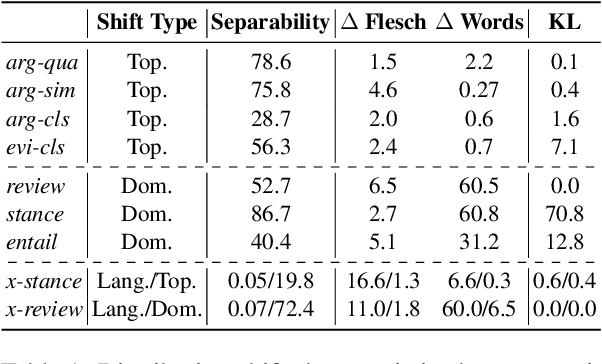
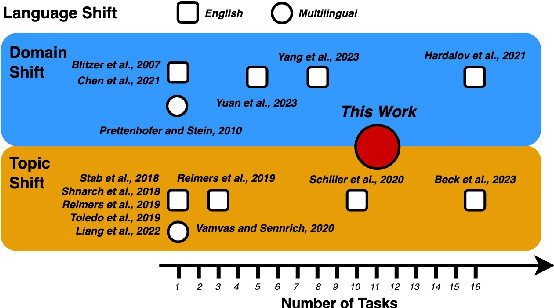
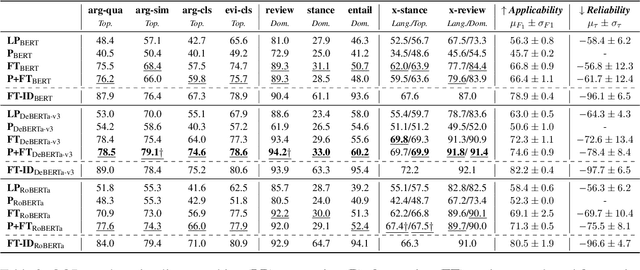
Language models (LMs) excel in in-distribution (ID) scenarios where train and test data are independent and identically distributed. However, their performance often degrades in real-world applications like argument mining. Such degradation happens when new topics emerge, or other text domains and languages become relevant. To assess LMs' generalization abilities in such out-of-distribution (OOD) scenarios, we simulate such distribution shifts by deliberately withholding specific instances for testing, as from the social media domain or the topic Solar Energy. Unlike prior studies focusing on specific shifts and metrics in isolation, we comprehensively analyze OOD generalization. We define three metrics to pinpoint generalization flaws and propose eleven classification tasks covering topic, domain, and language shifts. Overall, we find superior performance of prompt-based fine-tuning, notably when train and test splits primarily differ semantically. Simultaneously, in-context learning is more effective than prompt-based or vanilla fine-tuning for tasks when training data embodies heavy discrepancies in label distribution compared to testing data. This reveals a crucial drawback of gradient-based learning: it biases LMs regarding such structural obstacles.