 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting offline handwritten text recognition in historical documents with few labeled lines
Paper and Code
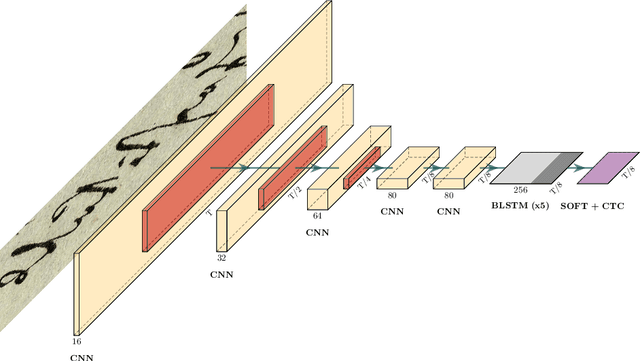
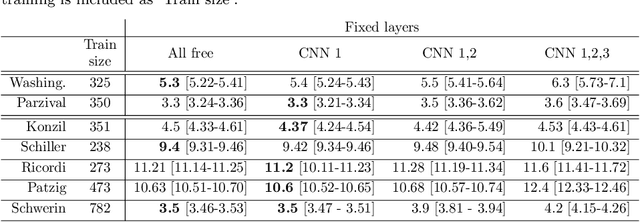
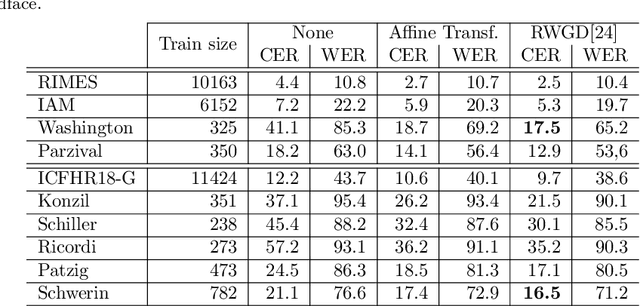
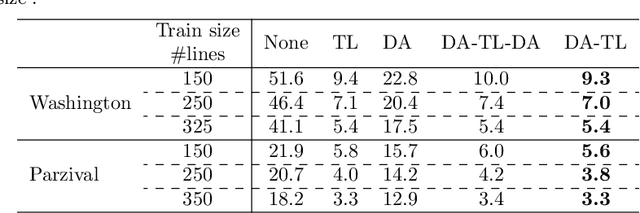
In this paper, we face the problem of offline handwritten text recognition (HTR) in historical documents when few labeled samples are available and some of them contain errors in the train set. Three main contributions are developed. First we analyze how to perform transfer learning (TL) from a massive database to a smaller historical database, analyzing which layers of the model need a fine-tuning process. Second, we analyze methods to efficiently combine TL and data augmentation (DA). Finally, an algorithm to mitigate the effects of incorrect labelings in the training set is proposed. The methods are analyzed over the ICFHR 2018 competition database, Washington and Parzival. Combining all these techniques, we demonstrate a remarkable reduction of CER (up to 6% in some cases) in the test set with little complexity overhead.