 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting in Location Space
Paper and Code
Sep 04, 2013


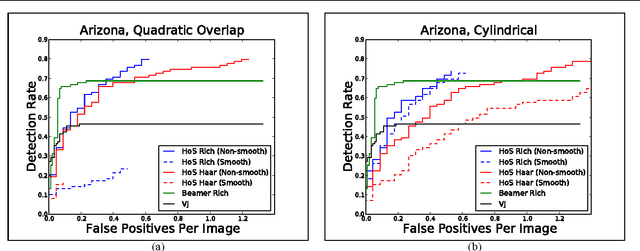
The goal of object detection is to find objects in an image. An object detector accepts an image and produces a list of locations as $(x,y)$ pairs. Here we introduce a new concept: {\bf location-based boosting}. Location-based boosting differs from previous boosting algorithms because it optimizes a new spatial loss function to combine object detectors, each of which may have marginal performance, into a single, more accurate object detector. A structured representation of object locations as a list of $(x,y)$ pairs is a more natural domain for object detection than the spatially unstructured representation produced by classifiers. Furthermore, this formulation allows us to take advantage of the intuition that large areas of the background are uninteresting and it is not worth expending computational effort on them. This results in a more scalable algorithm because it does not need to take measures to prevent the background data from swamping the foreground data such as subsampling or applying an ad-hoc weighting to the pixels. We first present the theory of location-based boosting, and then motivate it with empirical results on a challenging data set.