 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Handwriting Text Recognition in Small Databases with Transfer Learning
Paper and Code
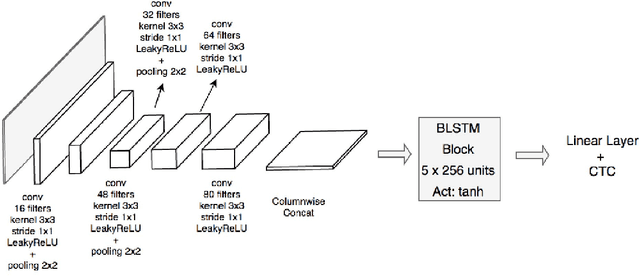

In this paper we deal with the offline handwriting text recognition (HTR) problem with reduced training datasets. Recent HTR solutions based on artificial neural networks exhibit remarkable solutions in referenced databases. These deep learning neural networks are composed of both convolutional (CNN) and long short-term memory recurrent units (LSTM). In addition, connectionist temporal classification (CTC) is the key to avoid segmentation at character level, greatly facilitating the labeling task. One of the main drawbacks of the CNNLSTM-CTC (CLC) solutions is that they need a considerable part of the text to be transcribed for every type of calligraphy, typically in the order of a few thousands of lines. Furthermore, in some scenarios the text to transcribe is not that long, e.g. in the Washington database. The CLC typically overfits for this reduced number of training samples. Our proposal is based on the transfer learning (TL) from the parameters learned with a bigger database. We first investigate, for a reduced and fixed number of training samples, 350 lines, how the learning from a large database, the IAM, can be transferred to the learning of the CLC of a reduced database, Washington. We focus on which layers of the network could be not re-trained. We conclude that the best solution is to re-train the whole CLC parameters initialized to the values obtained after the training of the CLC from the larger database. We also investigate results when the training size is further reduced. The differences in the CER are more remarkable when training with just 350 lines, a CER of 3.3% is achieved with TL while we have a CER of 18.2% when training from scratch. As a byproduct, the learning times are quite reduced. Similar good results are obtained from the Parzival database when trained with this reduced number of lines and this new approach.