Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiomedical term normalization of EHRs with UMLS
Paper and Code
May 24, 2018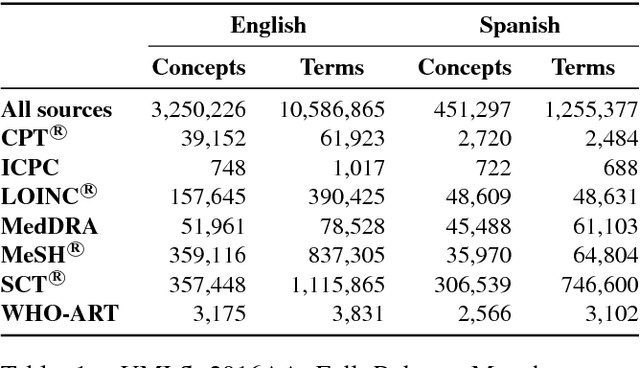
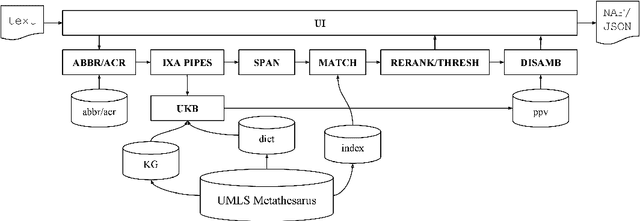
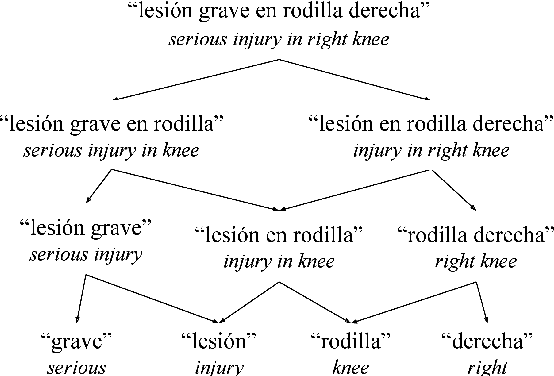

This paper presents a novel prototype for biomedical term normalization of electronic health record excerpts with the Unified Medical Language System (UMLS) Metathesaurus. Despite being multilingual and cross-lingual by design, we first focus on processing clinical text in Spanish because there is no existing tool for this language and for this specific purpose. The tool is based on Apache Lucene to index the Metathesaurus and generate mapping candidates from input text. It uses the IXA pipeline for basic language processing and resolves ambiguities with the UKB toolkit. It has been evaluated by measuring its agreement with MetaMap in two English-Spanish parallel corpora. In addition, we present a web-based interface for the tool.
* Perez, N., Cuadros, M., & Rigau, G. (2018). Biomedical term
normalization of EHRs with UMLS. In Proceedings of the Eleventh International
Conference on Language Resources and Evaluation (LREC 2018). ELRA
View paper on