 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBidirectional-Reachable Hierarchical Reinforcement Learning with Mutually Responsive Policies
Paper and Code
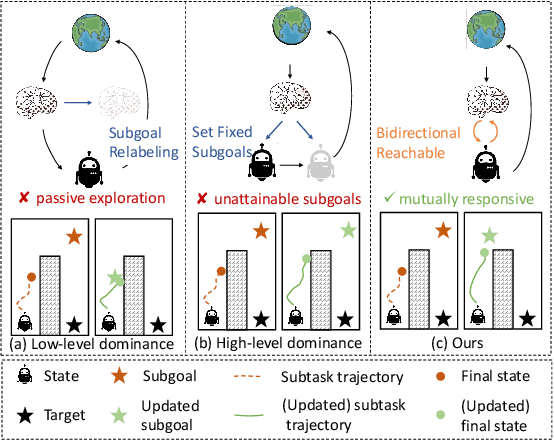
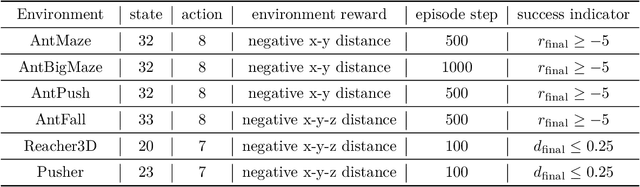
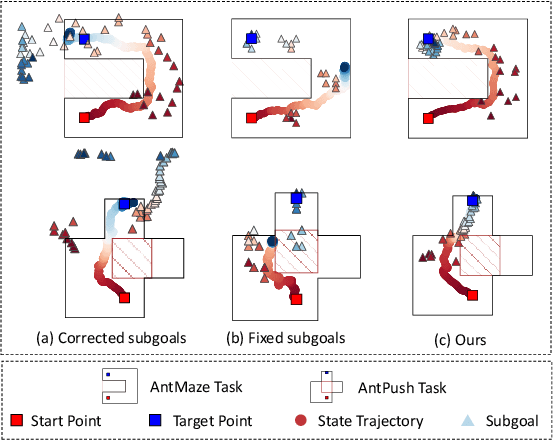
Hierarchical reinforcement learning (HRL) addresses complex long-horizon tasks by skillfully decomposing them into subgoals. Therefore, the effectiveness of HRL is greatly influenced by subgoal reachability. Typical HRL methods only consider subgoal reachability from the unilateral level, where a dominant level enforces compliance to the subordinate level. However, we observe that when the dominant level becomes trapped in local exploration or generates unattainable subgoals, the subordinate level is negatively affected and cannot follow the dominant level's actions. This can potentially make both levels stuck in local optima, ultimately hindering subsequent subgoal reachability. Allowing real-time bilateral information sharing and error correction would be a natural cure for this issue, which motivates us to propose a mutual response mechanism. Based on this, we propose the Bidirectional-reachable Hierarchical Policy Optimization (BrHPO)--a simple yet effective algorithm that also enjoys computation efficiency. Experiment results on a variety of long-horizon tasks showcase that BrHPO outperforms other state-of-the-art HRL baselines, coupled with a significantly higher exploration efficiency and robustness.