 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBias-Variance Tradeoffs in Single-Sample Binary Gradient Estimators
Paper and Code
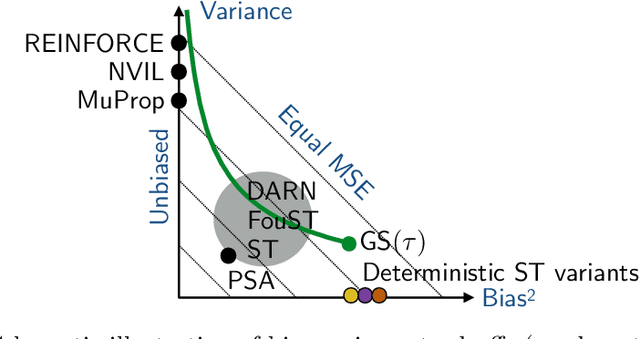

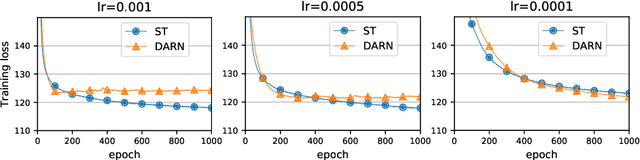
Discrete and especially binary random variables occur in many machine learning models, notably in variational autoencoders with binary latent states and in stochastic binary networks. When learning such models, a key tool is an estimator of the gradient of the expected loss with respect to the probabilities of binary variables. The straight-through (ST) estimator gained popularity due to its simplicity and efficiency, in particular in deep networks where unbiased estimators are impractical. Several techniques were proposed to improve over ST while keeping the same low computational complexity: Gumbel-Softmax, ST-Gumbel-Softmax, BayesBiNN, FouST. We conduct a theoretical analysis of bias and variance of these methods in order to understand tradeoffs and verify the originally claimed properties. The presented theoretical results allow for better understanding of these methods and in some cases reveal serious issues.