 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter than classical? The subtle art of benchmarking quantum machine learning models
Paper and Code
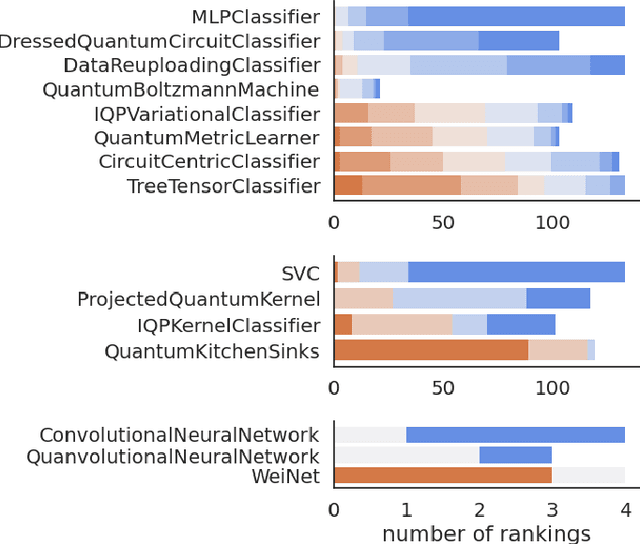
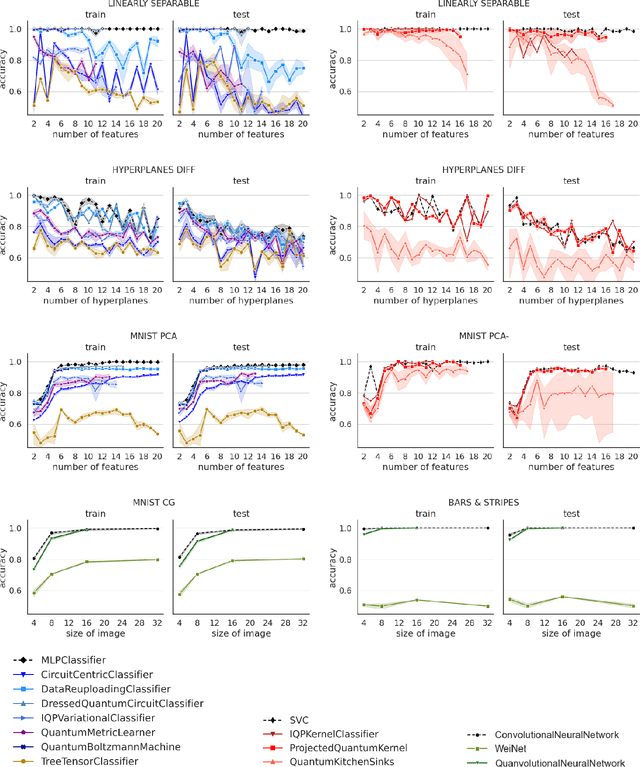

Benchmarking models via classical simulations is one of the main ways to judge ideas in quantum machine learning before noise-free hardware is available. However, the huge impact of the experimental design on the results, the small scales within reach today, as well as narratives influenced by the commercialisation of quantum technologies make it difficult to gain robust insights. To facilitate better decision-making we develop an open-source package based on the PennyLane software framework and use it to conduct a large-scale study that systematically tests 12 popular quantum machine learning models on 6 binary classification tasks used to create 160 individual datasets. We find that overall, out-of-the-box classical machine learning models outperform the quantum classifiers. Moreover, removing entanglement from a quantum model often results in as good or better performance, suggesting that "quantumness" may not be the crucial ingredient for the small learning tasks considered here. Our benchmarks also unlock investigations beyond simplistic leaderboard comparisons, and we identify five important questions for quantum model design that follow from our results.