 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBERT-Assisted Semantic Annotation Correction for Emotion-Related Questions
Paper and Code
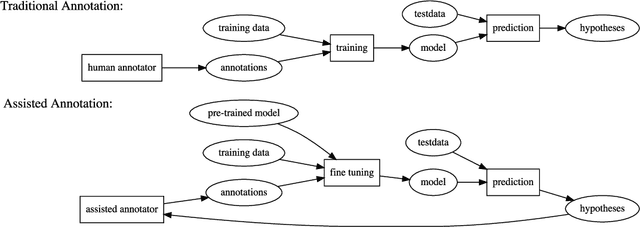
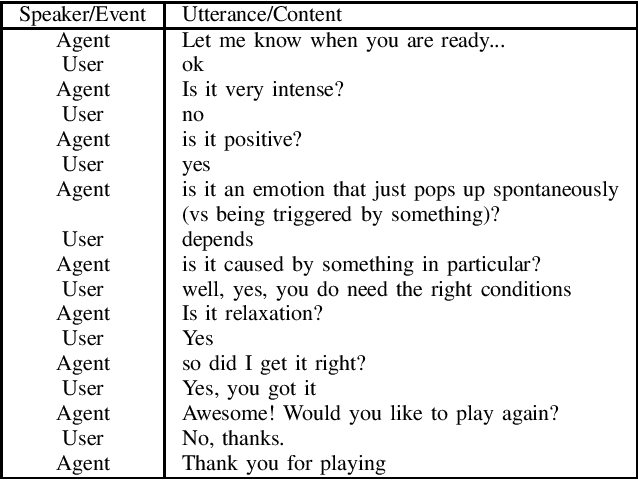

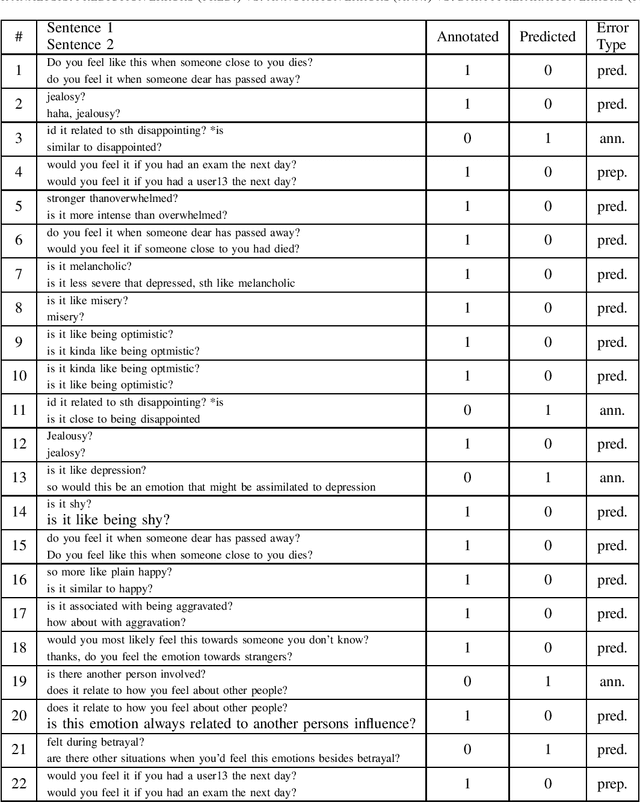
Annotated data have traditionally been used to provide the input for training a supervised machine learning (ML) model. However, current pre-trained ML models for natural language processing (NLP) contain embedded linguistic information that can be used to inform the annotation process. We use the BERT neural language model to feed information back into an annotation task that involves semantic labelling of dialog behavior in a question-asking game called Emotion Twenty Questions (EMO20Q). First we describe the background of BERT, the EMO20Q data, and assisted annotation tasks. Then we describe the methods for fine-tuning BERT for the purpose of checking the annotated labels. To do this, we use the paraphrase task as a way to check that all utterances with the same annotation label are classified as paraphrases of each other. We show this method to be an effective way to assess and revise annotations of textual user data with complex, utterance-level semantic labels.