 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Detection Transfer Learning with Vision Transformers
Paper and Code

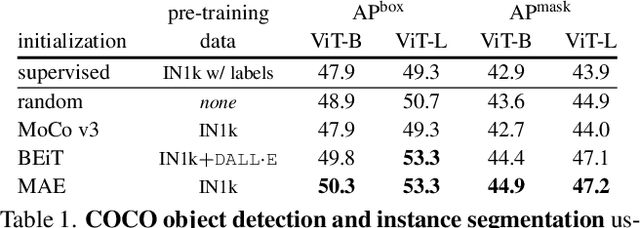
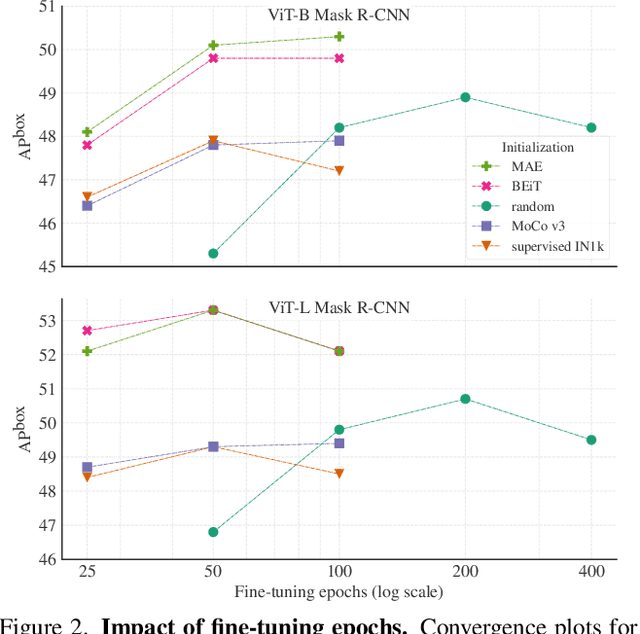

Object detection is a central downstream task used to test if pre-trained network parameters confer benefits, such as improved accuracy or training speed. The complexity of object detection methods can make this benchmarking non-trivial when new architectures, such as Vision Transformer (ViT) models, arrive. These difficulties (e.g., architectural incompatibility, slow training, high memory consumption, unknown training formulae, etc.) have prevented recent studies from benchmarking detection transfer learning with standard ViT models. In this paper, we present training techniques that overcome these challenges, enabling the use of standard ViT models as the backbone of Mask R-CNN. These tools facilitate the primary goal of our study: we compare five ViT initializations, including recent state-of-the-art self-supervised learning methods, supervised initialization, and a strong random initialization baseline. Our results show that recent masking-based unsupervised learning methods may, for the first time, provide convincing transfer learning improvements on COCO, increasing box AP up to 4% (absolute) over supervised and prior self-supervised pre-training methods. Moreover, these masking-based initializations scale better, with the improvement growing as model size increases.