 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehavior Estimation from Multi-Source Data for Offline Reinforcement Learning
Paper and Code
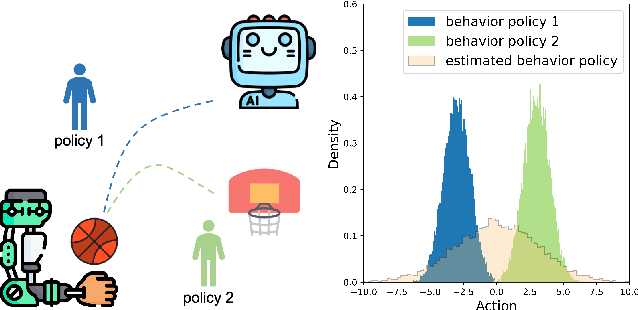
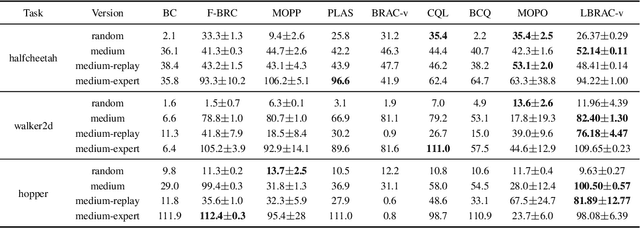
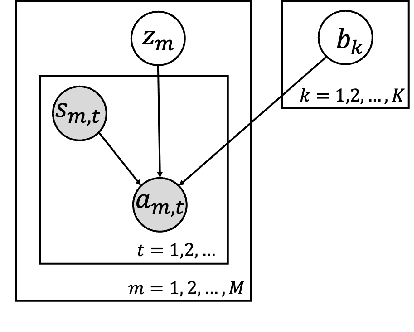
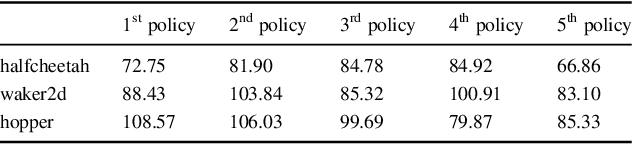
Offline reinforcement learning (RL) have received rising interest due to its appealing data efficiency. The present study addresses behavior estimation, a task that lays the foundation of many offline RL algorithms. Behavior estimation aims at estimating the policy with which training data are generated. In particular, this work considers a scenario where the data are collected from multiple sources. In this case, neglecting data heterogeneity, existing approaches for behavior estimation suffers from behavior misspecification. To overcome this drawback, the present study proposes a latent variable model to infer a set of policies from data, which allows an agent to use as behavior policy the policy that best describes a particular trajectory. This model provides with a agent fine-grained characterization for multi-source data and helps it overcome behavior misspecification. This work also proposes a learning algorithm for this model and illustrates its practical usage via extending an existing offline RL algorithm. Lastly, with extensive evaluation this work confirms the existence of behavior misspecification and the efficacy of the proposed model.