 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Stratified Sampling to Assess Corpus Utility
Paper and Code
Jun 19, 1998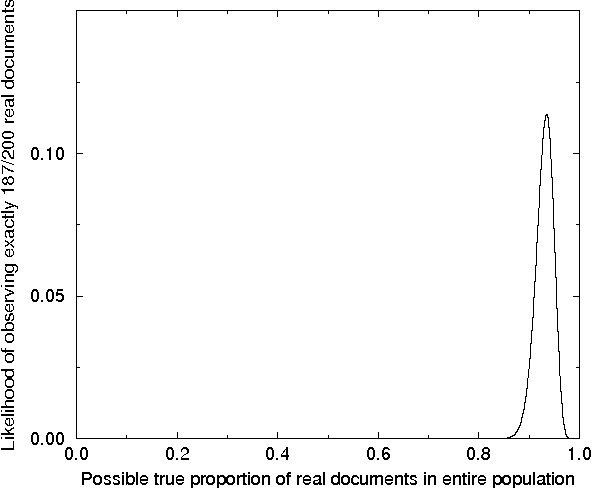
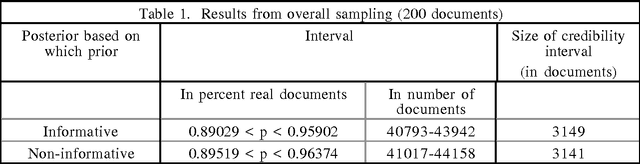
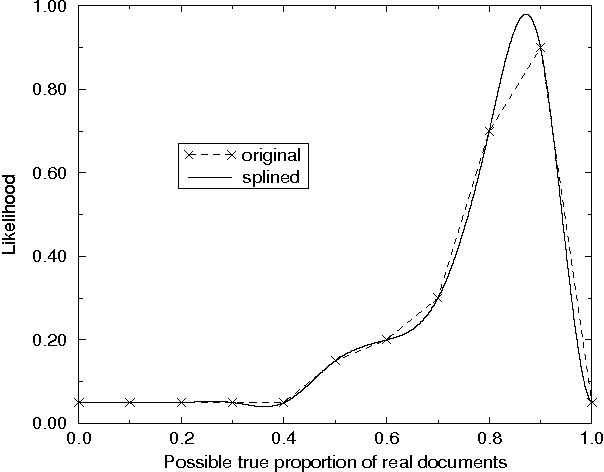
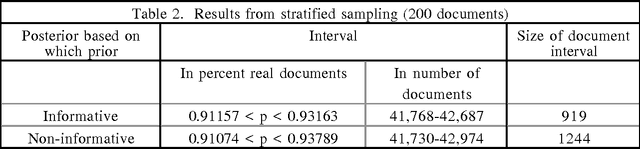
This paper describes a method for asking statistical questions about a large text corpus. We exemplify the method by addressing the question, "What percentage of Federal Register documents are real documents, of possible interest to a text researcher or analyst?" We estimate an answer to this question by evaluating 200 documents selected from a corpus of 45,820 Federal Register documents. Stratified sampling is used to reduce the sampling uncertainty of the estimate from over 3100 documents to fewer than 1000. The stratification is based on observed characteristics of real documents, while the sampling procedure incorporates a Bayesian version of Neyman allocation. A possible application of the method is to establish baseline statistics used to estimate recall rates for information retrieval systems.